1、特斯拉马斯克Robotaxi演讲实录:最快2026年量产,成本不超3万美元
2、曝海康威视裁员上千人:赔偿N+2,研发部门是重灾区
3、曝字节跳动马来西亚裁员700人 内容审核转向AI
4、英伟达独霸GPU市场20年,未来几年仍无强劲对手
5、恢复增长!全球半导体封装材料市场预计明年达260亿美元
6、2nm之战全面打响!背面供电成制胜关键?
7、100亿美元估值被砍一半,贝恩资本放弃铠侠IPO计划
1、特斯拉马斯克Robotaxi演讲实录:最快2026年量产,成本不超3万美元

美国当地时间10月10日晚(北京时间10月11日上午),特斯拉在“We, Robot”主题发布会上,正式发布Robotaxi(无人驾驶出租车),并命名为Cybercab,如下是特斯拉CEO马斯克的演讲全文:
欢迎大家!我们今天晚上给大家准备了一场非常精彩的展示,我相信大家应该都会喜欢的。
正如大家所见,我刚刚就搭乘着我们的Robotaxi无人驾驶出租车来到了这里,外面还有20多辆这样的车,这些Robotaxi一直都在路上行驶,而且车里是没有人驾驶的。
今天晚上我们会有50辆搭载了完全自动驾驶能FSD的汽车在这边,大家可以看到有Model Y,也有Cybercab,全部都是无人驾驶的。Cybercab里面没有方向盘,也没有踏板。
今天我们希望大家体现到的未来,是一个更加光明的未来,就像我们在考虑今天的交通的时候,有很多非常让人痛苦的通勤。如果你在洛杉矶开车的话,通勤可能会很久,除非你开的是特斯拉,因为特斯拉已经做得很好了,我指的就是有驾驶员监督情况下的FSD已经做得很好了。

相信今天在场的各位应该有人已经使用了我们的监督版FSD完全自动驾驶能力,我们的FSD也会从有人监督的模式转向无人监督的完全自动驾驶模式,我们可以直接上车,然后车就可以自动把我们带去我们需要的目的地。
当然这里也还有一个挑战,就是车辆的制造成本,要开车就需要花钱,买车要钱,保险也要钱,汽车停放也需要钱,真的非常贵。
与此同时,我们要想一下车的使用频率,多久用一次?一周有168小时,一辆车每周可能只会用10~100小时,大部分时候车什么都不做,我们的车是完全自动驾驶的,我们可以将它的使用率提高5倍甚至10倍。
在同一辆车身上,我们可以获得5倍或10倍的价值提升,每周其使用时间就可以突破100小时,甚至达到160多个小时,我们自己开车,很多时候都在寻找车位,让我们感到非常的烦恼,我们希望通过自动驾驶让这样的问题不复存在。因此我们的Robotaxi真的是非常棒的产品。
Robotaxi其安全性还可以大幅提升,可以拯救生命,防止人们受伤,我认为FSD实现的安全水平可以超过人类驾驶10倍左右。
过去电梯是怎么运行的?里边坐了电梯操作员,但是现在没有这样的操作员了,按一下按钮就可以到达所需楼层,车也是这样发展进化的,车以后也会是类似的。
我刚才提到安全性,这真的非常重要,人们在车里边花的时间非常多,我们希望车能够保持最高的安全性,人们在车上花的时间可能与在手机上花的时间类似。
人们在手机上做什么?可以处理工作,可以看电影,可以做其他很多事情。
如果车可以自己驾驶自己,那车内空间可以成为一种小的休息室,人们在这里可以享用愉快的时光,在这里我们什么也不用干,或者干自己想干的事情,车就可以带我们想去的目的地,这真的非常棒对吧?
在成本方面,我们认为自动驾驶的成本会非常低,这是个性化的公共交通运输,平均成本可以大幅降低。
这里,我们其实是可以综合考虑。现在的成本还是挺高的,我认为Cybercab的成本可能会随着我们业务进一步铺开,降低到0.2美元每英里左右,而现在我们看到交通成本是挺高的,每英里可能会高达1美元左右。
大家都可以拥有这样的出行服务,我们期待车辆成本应该会低于3万美元这样的水平。通过这样的车辆,我们可以开辟新的商业模式。
我们希望我们的车队管理可以非常高效,非常少的人就可以管理大规模的车队,就像牧羊人照顾他们的羊群一样,一个人就可以管理非常大的车队,我认为这样的未来是非常光明的,这也是非常独特的事情。
其实我们一直在努力实现完全自动驾驶,在很多年时间中,我们一直在思考Model 3和Model Y已经有非常不错的FSD能力,现在我们又谈论Cybercab。
其实对于这样的产品推出的时间线我们还是比较乐观的,我们期望很快能够实现完全的无人监督FSD,明年在德州和加州,我们希望推出完全的无人监督的FSD,很明显,Model 3和Model Y是沿着这样的道路前进,我们预计下边会非常快的投产,针对自主或者说自动运输,我们实现了高度的优化。
对于整条时间线,我们持乐观的态度,2026年或许是2027年之前我们会大规模铺开这样的产品,我们将以非常大的量来生产Cybercab,在那之前,Model 3、Model Y、Model S等,他们的能力也会进一步提升。Model 3和Model Y将实现无人监督的FSD。
在监管方面,我们希望进一步去跟踪相关动态。美国的监管机构是我们首先会沟通的,之后在美国以外其他地方我们也会跟进监管的动态。
在Cybercab的发展路线上,我们在未来会推出Cybercab 2,我们所有的车都会有非常不错的FSD能力。我们现在有数百万辆车在接受训练,这就像有数百万个用例在实时的去收集数据并且进行训练。
其实每一辆车它都有自己不同的使用场景,就像是数百万个生命在不停的发展,我们有这么多训练数据,显然FSD驾驶水平会比人类高得多,人不可能活100万次,但是我们有这么多的车一直在收集不同的数据,通过数据来不停的训练和优化,最终数据训练的结果,FSD让我们的车辆比人类驾驶更安全。我们解决方案是基于AI和计算机视觉,因此不需要非常昂贵的设备。
我们今天已经在放低Model 3、Model Y、Model S等车辆的生产成本。
我们希望在Cybercab这一侧,也会去实现更好的硬件规格,那就是我们说的AI 5。我想AI 5在某种程度上是一种新的规范,如果一辆车每周行驶50小时,那么还剩100多小时可以利用,这就意味着还有非常多的算力是空闲的。如果我们有了车队,那这加起来会有多少的算力?那是非常多的。
因为这个车并不是每时每刻都在运行中,在闲置的时候算力就可以集成起来使用,我认为这非常有道理,逻辑也非常清晰,那自动驾驶的未来在这一块也会有更大的价值。
我们设想的车没有方向盘,没有踏板,没有控制装置,这感觉真的非常棒。我们这里有非常多这样的车。这里我们也有设置非常多的不同场景,让车在不同场景去运行。我们希望车在这里可以行驶挺长一段时间,我们将这里的场景设置的比较乱,我们看一下这样的车是否可以真正的安全、顺畅地行驶过这样的空间。
此外我们还有感应充电,这是无线的,这就是我们应该去追求的充电方式。
有一件事情相当有趣,那就是我们到底如何通过我们的产品和技术来影响我们所居住的城市。当我们开车去城市里转悠时,会看到很多停车场,甚至有些城市到处都是停车场,如果整个出行环境都变成自动驾驶,其实停车场可以变成公园。
大家看一下在这里我们可以从不同的角度来观察停车空间,自动驾驶真的可以将停车场变得更美丽,甚至成为公园,这里有很多的机会让城市也变得更美好。我们所居住的城市有非常多这样的停车空间,这些停车空间可以变成绿色的空间,真的是非常棒的。
对于车的尺寸,不同的车主有不同的需求,如果大家需要比Model Y更大的车怎么办?我们这里就有Cybervan,看起来是挺大的。大家想象一下,在街上看到这辆车是否会感觉到有非常强的未来感,好像是星球大战里边的东西,这辆车可以搭载20人,也可以运输货物。
大家想一下这样的车对于城市、对于出行有了什么?Cybervan可以以非常高的密度来实现更高效的出行,成本也可以大幅降低,每英里大概是5~10美分,Cybervan出行体验可以进一步提升,出行的成本可以大幅降低。
其实之前,在我们的赛博旅行车上也看到了类似的特征,我们希望出行在我们的努力下得以改变,道路的外观在未来也会发生改变,未来应该更像未来。
接下来谈一下机器人(Optimus),大家会想到什么?我们为车开发了很多东西,包括电池、电力、电子设备、高级电机、变速箱、软件、推理设备等,这一切都可以用于人形机器人,因为这些技术是通用的,我们可以将技术整合到机器人上,机器人有胳膊、有腿,而不是有轮子的机器人。
总体看来,它和人的形状差不多,在人形机器人上我们取得了不错的进展,我们有一排机器人在这里,他们都有自己的套装,我们年复一年的在此方面取得巨大进步,这样的机器人到底可以做什么?
其实任何人都可以拥有这样的机器人,大家可以拥有自己个人的人形机器人,我们可以从规模的角度来考虑一下,如果机器人大规模部署将会怎么样?
如果规模铺开,成本也会大幅降低,可能两、三万美元,比一辆车还便宜一些,我们需要花一点时间来长期的优化这个产品,从根本上来讲,我们的人形机器人真的可以实现更多的可能性。
我认为,以后我们可以做到两、三万美元,就可以为大家提供一台这样的人形机器人,它可以做任何大家想做的事情,比如照顾孩子、遛狗、修剪草坪、去超市买东西,也可以为大家端一杯咖啡过来,大家想到日常的这些事情他都可以做。
作为伟大的产品,我认为全球80亿人每个人都应该想要这样的产品,这样的产品真的是非常好的伙伴,对吧?我想在地球上的80亿人里面,其实都会希望有像奥特曼这样的人形机器人伙伴。
2、曝海康威视裁员上千人:赔偿N+2,研发部门是重灾区

据新浪科技报道,海康威视员工日前透露,公司近期正进行大规模组织调整,32个研发区域收缩到12个,预计会涉及1000多员工的优化。目前已有海康威视被裁员工确认此事,“会有N+2赔偿,研发部门是重灾区。湖南等区域已经没了,但杭州等总部地区还没开始。”
对此,海康威视方面回应称,公司不存在大规模裁员,是经营策略调整,需要优化总部及重点销售城市的研发力量,因此相应调整了部分区域岗位设置。
自2010年上市以来,海康威视在保持了近10年的高速业绩增长后,近几年开始出现营收及净利润下滑情况。2022年全年及2023年前三季,海康威视净利年增率大幅下滑。而在2024年上半年,海康威视再次出现净利按年下滑的情况。
2024上半年,海康威视实现营业总收入412.09亿元,比上年同期增长9.68%;实现归属于上市公司股东的净利润50.64亿元,比上年同期下降5.13%;实现归属上市公司股东的扣除非经常性损益的净利润52.43亿元,比上年同期增长4.11%。
国内主业方面,上半年三个BG营收总和189.71亿元,比上年同期下降0.26%,占公司营收46%。其中公共服务事业群PBG实现营收56.93亿元,同比下降9.25%;企事业事业群EBG实现营收74.89亿元,同比增长7.05%;中小企业事业群SMBG实现营收57.89亿元,同比增长0.64%。总体而言,今年上半年收入增长情况主要受资金方面的影响较为明显,依赖地方财政资金投入的行业普遍比较困难;依靠自身资金为主发展的行业,保持一定的投资。
境外主业方面,上半年实现营收114.41亿元,同比增长15.46%,海外主业收入占公司业务比重约28%(海外主业不含创新业务的海外收入,如果加入创新业务的海外收入,海外收入占比34.41%)。受美国制裁影响,美国营收继续下行,收入占比持续降低;剔除美国市场影响,美洲、泛欧、泛亚太、中东非四个大区均实现增长。
创新业务方面,上半年实现营收103.28亿元,同比增长26.13%,占公司业务比重达25%。
另外,上半年毛利率为45.05%,与上期相比基本保持稳定;本期的汇兑损失约为8100万元,去年同期产生的汇兑收益约为2.85亿元,两者的账面差异对本期净利润产生较大影响;存货方面,公司整体策略维持,对于部分供应来源更丰富的原材料,存货水位予以下调。
3、曝字节跳动马来西亚裁员700人 内容审核转向AI

两位知情人士透露,中国社交媒体平台TikTok的母公司字节跳动马来西亚子公司解雇700多名员工,因为该公司将重点转向在内容审核中更多地使用人工智能(AI)。
匿名消息人士称,这些员工大多参与了公司的内容审核工作,他们于周三(10月9日)晚间通过电子邮件收到了被解雇的通知。
TikTok于10月11日在回应媒体的询问时,证实了裁员的消息,但表示无法透露马来西亚受影响员工的具体人数。
作为改善其审核运作的更广泛计划的一部分,该公司预计全球将有数百人受到影响。TikTok采用自动检测和人工审核相结合的方式审查网站上发布的内容。
据该公司网站称,字节跳动在全球200多个城市拥有超过11万名员工。
一位消息人士称,该科技公司还计划下个月进行更多裁员,以整合部分地区业务。
TikTok发言人在一份声明中表示:“我们做出这些改变是我们持续努力进一步加强内容审核全球运营模式的一部分。”
该发言人表示,公司预计今年将在全球范围内投资20亿美元用于信任和安全,并将继续提高效率,目前80%的违反准则的内容已通过自动化技术删除。
此次裁员正值跨国科技公司在马来西亚面临越来越大的监管压力之际,马来西亚政府要求社交媒体运营商在明年1月之前申请运营许可证,以打击网络犯罪。
马来西亚今年早些时候报告称社交媒体有害内容急剧增加,并敦促包括TikTok在内的公司加强对其平台的监控。
4、英伟达独霸GPU市场20年,未来几年仍无强劲对手

英伟达应该称为人工智能(AI)公司还是消费级GPU公司?3DCenter最新汇编显示,英伟达在过去二十年中一直占据独立GPU市场的主导地位,AMD毫无优势。
在AI出现之前,英伟达专注于消费级和专业级GPU;现在仍保持同样的地位,但形势有所不同,AMD份额创下新低。
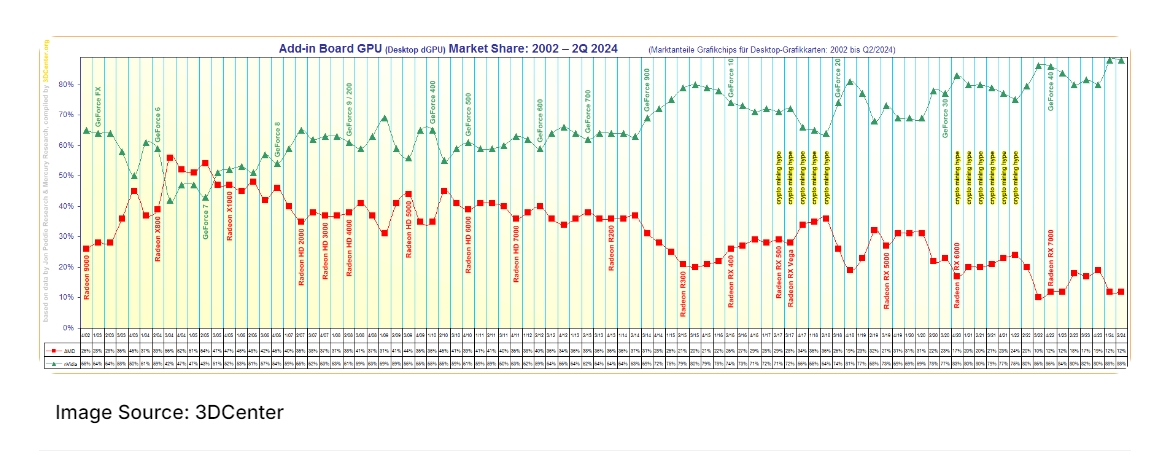
从GeForce FX系列台式机GPU开始,英伟达现在已经变成一个不仅主导台式机GPU市场,而且已被证明是AMD等公司巨大竞争对手的平台。根据3DCenter显示数据,英伟达自2002年以来一直主导着GPU市场份额,而且这种趋势仍在继续。
最初几年的竞争确实很激烈,当时AMD推出了Radeon X100系列,由于HDR渲染和CrossFire支持等技术的首次亮相,成功缩小了市场份额差距,但从那时起,就完全是英伟达的天下了。即使是现在,尽管将dGPU放在次要位置,但在消费者采用方面,该公司仍然占据主导地位。
英伟达及其巨大市场份额的关键时刻是在加密挖矿炒作期间,其市场份额飙升至80%。由于当时矿工对GeForce RTX 30系列GPU需求很高,英伟达充分利用了这一点,而AMD却未能成为焦点。从那时起,英伟达市场主导地位呈上升趋势,而且从目前的情况来看,这种趋势似乎还没有被打破。
英伟达的唯一竞争对手AMD现在已经回归主流市场,重振其Radeon游戏显卡业务,而英伟达即将推出新一代发烧友游戏解决方案。即使是英特尔也将主要应对主流市场,而英伟达在未来几年内没有强劲竞争对手。
无论是人工智能、机器人技术,还是消费级GPU领域,英伟达的存在对于各大领域市场的发展都至关重要,占据计算市场的头部地位。
5、恢复增长!全球半导体封装材料市场预计明年达260亿美元
近日,SEMI、TECHCET 和 TechSearch International在其最新的全球半导体封装材料展望 (GSPMO) 报告中宣布,受各种终端应用对半导体的强劲需求推动,全球半导体封装材料市场预计将开始增长周期,预计到 2028 年复合年增长率 (CAGR) 为 5.6%。该报告强调,尽管由于该细分市场尚属新兴,目前的单位产量较低,但人工智能仍是先进封装应用的预期增长动力。
GSPMO报告提供了基板、引线框架、键合线和其他先进封装材料的全面数据和预测。
TECHCET 总裁兼首席执行官 Lita Shon-Roy 表示:“2023 年半导体封装材料市场经历了 15.5% 的下滑,我们的最新报告预测 2024 年将恢复增长。预计到 2025 年,全球封装材料市场规模将超过 260 亿美元,并将持续稳步增长至 2028 年。”
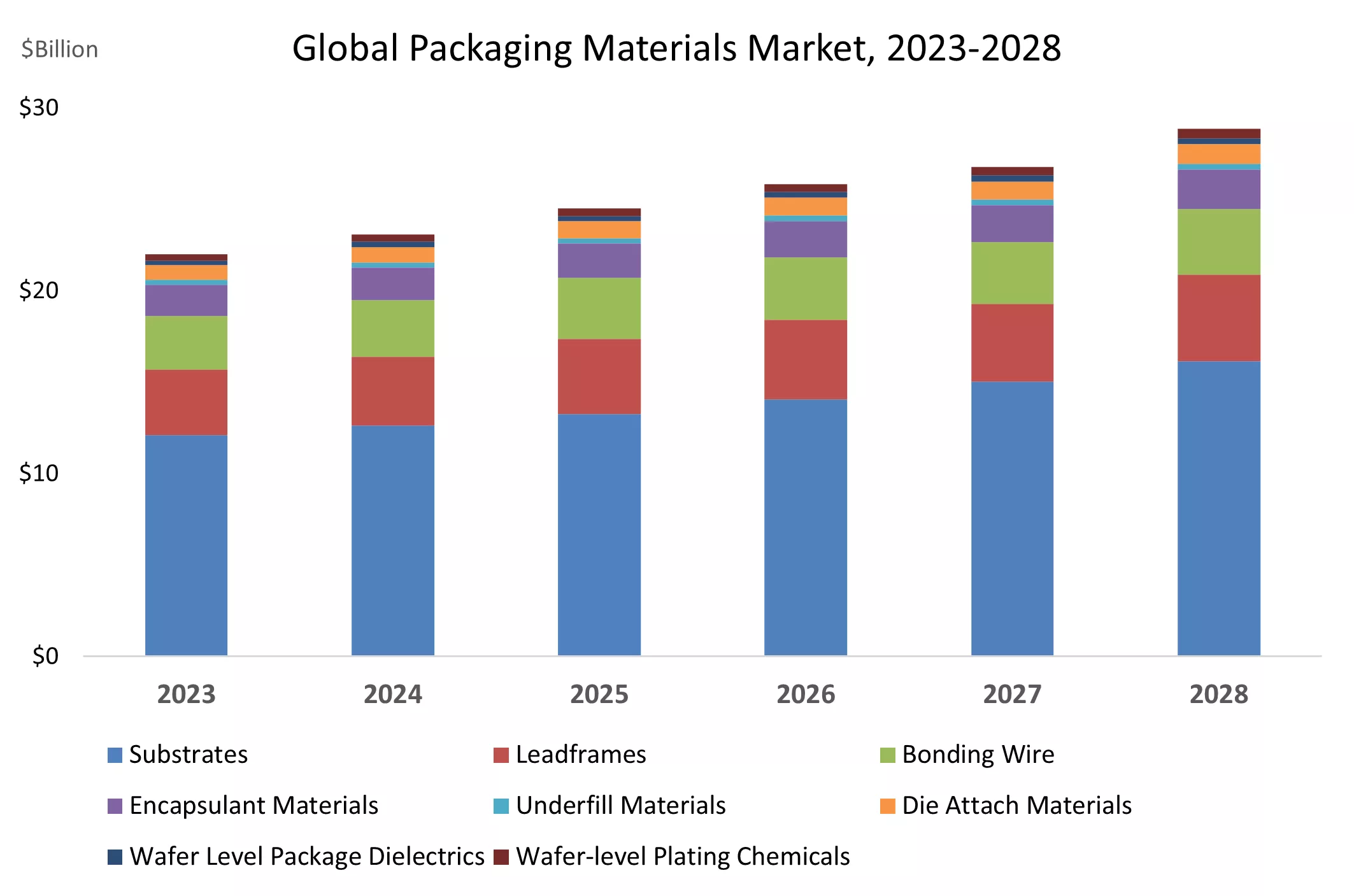
TechSearch International 总裁 Jan Vardaman 表示:“基板占封装材料市场收入的很大一部分,而在这一类别中,FC-BGA 基板占收入增长的大部分。”“从 2023 年到 2028 年,倒装芯片 BGA/LGA 收入的复合年增长率预计为 7.6%。其他关键增长领域包括晶圆级封装 (WLP) 电介质和倒装芯片底部填充。层压基板细分市场的年销量预计增长 7.3%,而引线框架和键合线也预计将复苏,分别增长 5.0% 和 6.4%。”
*https://www.semi.org/en/semi-press-releases/global-semiconductor-packaging-material-market-outlook-shows-return-to-growth-starting-in-2024
6、2nm之战全面打响!背面供电成制胜关键?
毫无疑问,目前台积电赢得了FinFET的战争。所有值得关注的前沿逻辑设计,甚至英特尔的设计,都是在台积电位于中国台湾南部的N5和N3工艺上制造的,竞争对手已被甩在后面。三星自7nm工艺以来性能一直表现不佳,且产量低下;英特尔4nm和3nm工艺仍处于复苏初期;无论是外部客户还是内部客户,都没有大批量订购这些节点的产品。
但台积电未来能否占据主导地位尚未可知。FinFET无法进一步扩展,而SRAM的微缩在几个节点上已经停滞。该行业正处于关键的转折点。在未来2~3年内,前沿逻辑设计必须采用两种新模式:全环绕栅极(GAA)和背面供电网络(BSPDN或backside power delivery network)。
英特尔在其10nm节点上一败涂地,失去了3年的领先优势,原因有很多,包括没有采用EUV光刻技术,以及在设备供应链不成熟的情况下过渡到钴金属化,尽管应用材料公司警告说他们的设备还没有准备好。GAA和BSPDN的新模式为代工厂的竞争顺序带来了新的机遇。他们甚至有可能为新进入者打开大门,比如日本政府支持的2nm晶圆代工初创公司Rapidus。
随着建造尖端晶圆厂所需的资本支出激增,这意味着三星或英特尔可能被迫退出竞争。下面我们将详细讨论这些话题:深入探讨BSPDN技术,然后介绍所有四家代工厂的前沿逻辑计划、其工艺技术的竞争力以及SRAM的缩放。
GAA并非新技术。根据三星的说法,它已经大批量生产了几年,但实际情况是,它只用于单个低容量比特币挖矿芯片,没有用于任何SRAM和小于20mm²的手表芯片。考虑到本世纪末,从2nm到更先进技术,所有前沿节点都将使用GAA架构,因此该架构是一个重要话题。
背面供电网络是什么?
除了GAA晶体管,BSPDN是下一代逻辑工艺技术的另一项关键创新。在目前所有的数字逻辑工艺技术中,首先要在晶圆上制造晶体管,然后再制造数十层金属层,这些金属层为晶体管供电,并在晶体管与外界之间传输信号。
电路的缩小意味着晶体管和互连都必须缩小。在过去,这几乎是一个事后考虑的问题,但现在缩放互连变得比缩放晶体管更加困难。例如,大多数EUV光刻实际上用于互连(触点、通孔和金属层),而不是晶体管层本身。除了导线本身的物理尺寸缩小,芯片上更多的晶体管意味着更多的互连。这推动了所需互连层数的稳步增长。层数越多,意味着制造成本越高,布线设计越困难,并且随着信号路径变长,性能会降低。
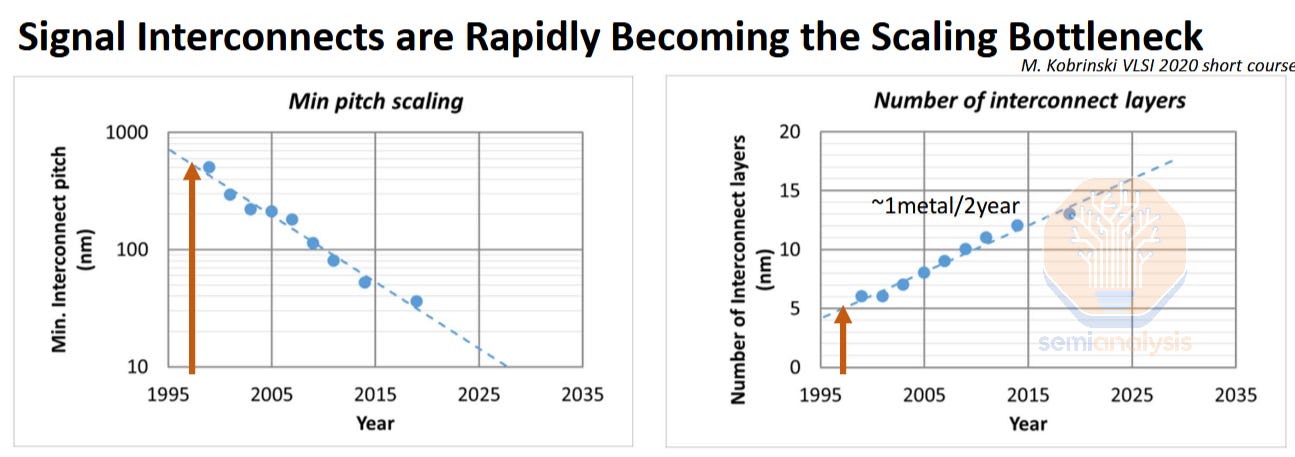
来源:英特尔IEDM2023
这并不意味着该行业停止了进步。材料创新、设计技术协同优化(DTCO)和EUV光刻技术推动了互连微缩至当前的工艺节点。但是,随着这种策略变得越来越昂贵,限制也在不断扩大。实施BSPDN开始变得有意义。这并不是什么新想法,只是时机已到。自上次互连技术演变——1997年从铝到铜的转变以来,已经过去了近30年。
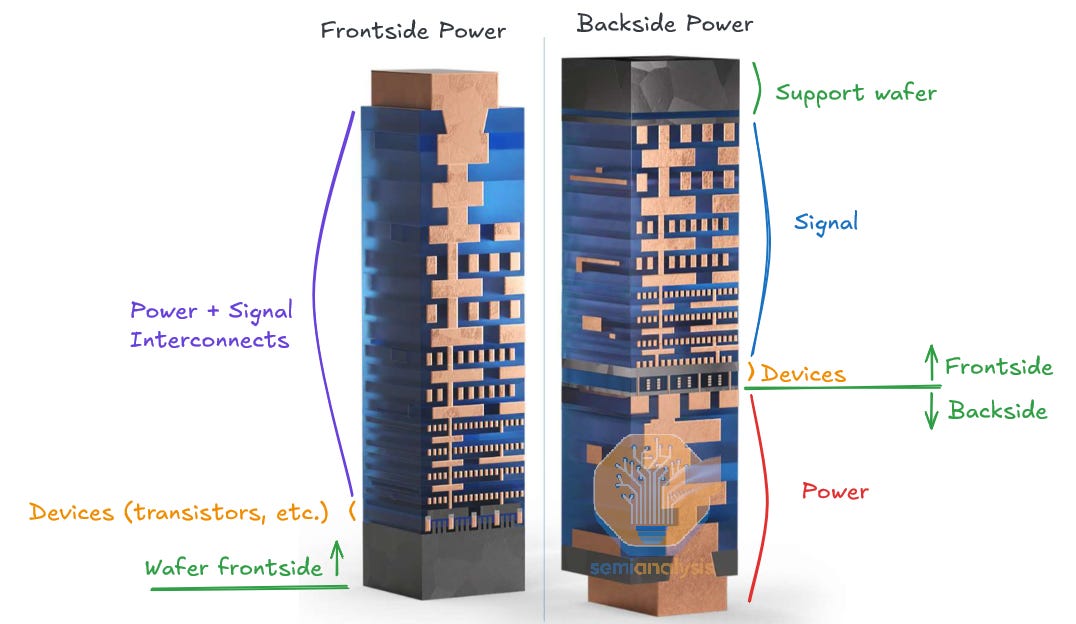
资料来源:英特尔,SemiAnalysis
BSPDN的核心理念是将电源布线移到晶圆背面。这为信号布线和电源开辟了空间,信号布线留在正面,而电源则移到背面。从架构上讲,这意味着短于6T(轨道)的标准单元更加可行。
6T是指标准单元的单元高度,标准单元是数字逻辑的基本构件,如NAND门,单元高度通常以T的倍数来衡量,即单元所跨金属2线或“轨道”的数量。越短越好:较小的单元可提高密度,而无需扩展鳍片、栅极和金属互连等底层功能。扩展更多功能的成本很高,因为这需要更好的光刻技术。
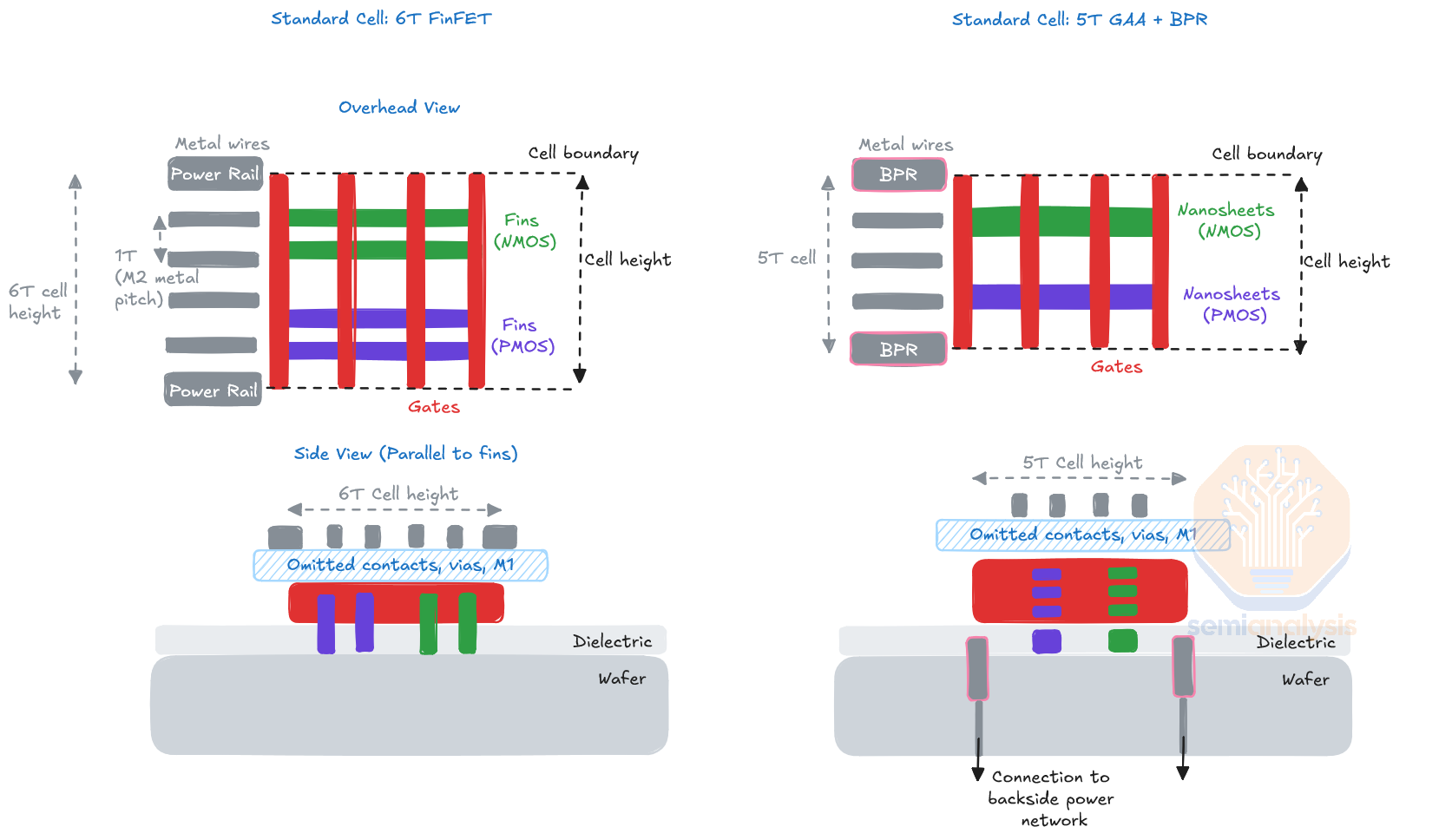
标准单元规模FinFET与GAA +埋入式电源轨对比。资料来源:SemiAnalysis
从上方看,标准单元的顶部和底部由M2金属层中的宽金属轨连接。这些导轨为单元提供电源和基准电压,并与更高金属层中的其余供电网络连接。这些导轨是典型正面单元6T总高度的一部分,将它们移到背面意味着单元可以缩小到5T或更短。
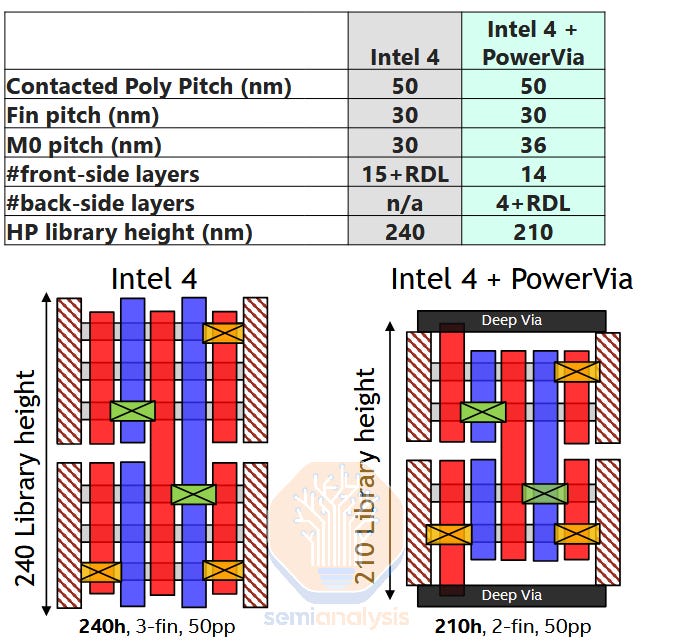
BSPDN的架构优势:添加PowerVia可通过缩短单元来提高密度,同时通过放宽M0间距来降低成本。来源:英特尔
BSPDN还在两个方面改善了功率传输。首先,向晶体管供电的互连长度大大缩短。在3nm节点上,仅正面供电就必须穿过15层以上的金属层,而背面供电可能只包括不到5层,而且导线更粗(电阻更低)。因此,线路电阻造成的功率损耗大约可以减少一个数量级。
其次,BSPDN减少了积极扩展互连的必要性。在100nm以下的系统中,随着铜线直径的缩小,铜线的电阻会呈指数增加。而现在,前沿技术的线宽已远低于20nm,电阻已成为一个关键问题。这是不可取的,因为高线路电阻会浪费功率并在芯片中产生过多热量。这并不是一个永久性的解决方案,缩放仍将继续,也需要铜替代品,但BSPDN可以缓解这一问题。
总体而言,在高性能设计中,BSPDN与类似的纯正面工艺相比,功耗大约可降低15%~20%。
目前正在探索和/或实施的背面供电传输有三种不同的方法:埋入式电源轨、电源通孔和背面接触。
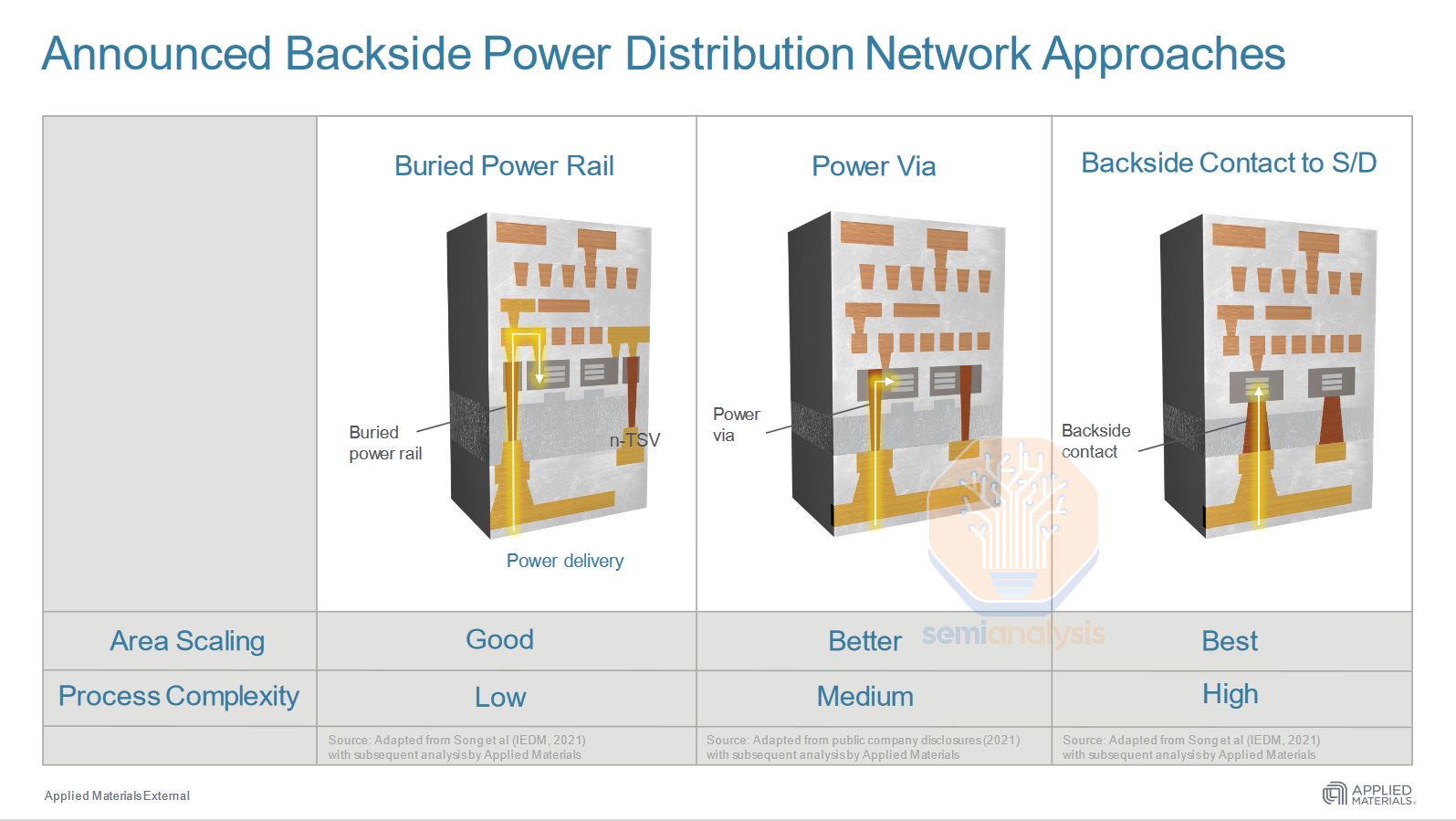
资料来源:应用材料公司
一、埋入式电源轨
埋入式电源轨(BPR)是最简单的背面供电实现方法。早期的研究采用了这一方案,随后的架构也在这一核心思想的基础上进行了改进。它要求将电源轨从M2金属层晶体管上方的正常位置移到晶体管下方的独立层。这样,宽大的电源轨被紧贴在晶体管下方的细高轨所取代,从而实现了架构上的缩小。不过,埋入式电源轨仍通过正面金属层与晶体管连接,并通过硅通孔(TSV)与背面的电源传输网络连接。这意味着整个单元的高度可以减少约1T,即大约15%。
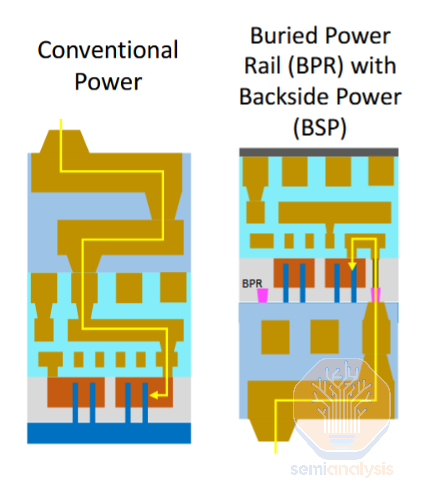
传统与BPR:在晶圆正面晶体管下方制造埋入式电源轨,然后连接至背面电源网络。来源:英特尔
构建BPR相对简单,但有一个主要风险:在前道工艺(FEOL)使用金属。传统上,在晶体管制造完成后,金属仅限于中间工序(MOL)和后道工艺(BEOL)工艺。这是为了避免导电金属污染半导体器件。晶圆厂对此非常重视,许多制造厂都配备了FEOL专用工具,禁止运行任何带有金属层的晶圆。晶圆厂必须打破这一规则,构建埋入式电源轨,因为根据定义,BPR必须在晶体管之前集成。实际上,没有人愿意打破这一规则,而且任何HVM工艺似乎都不会采用BPR。
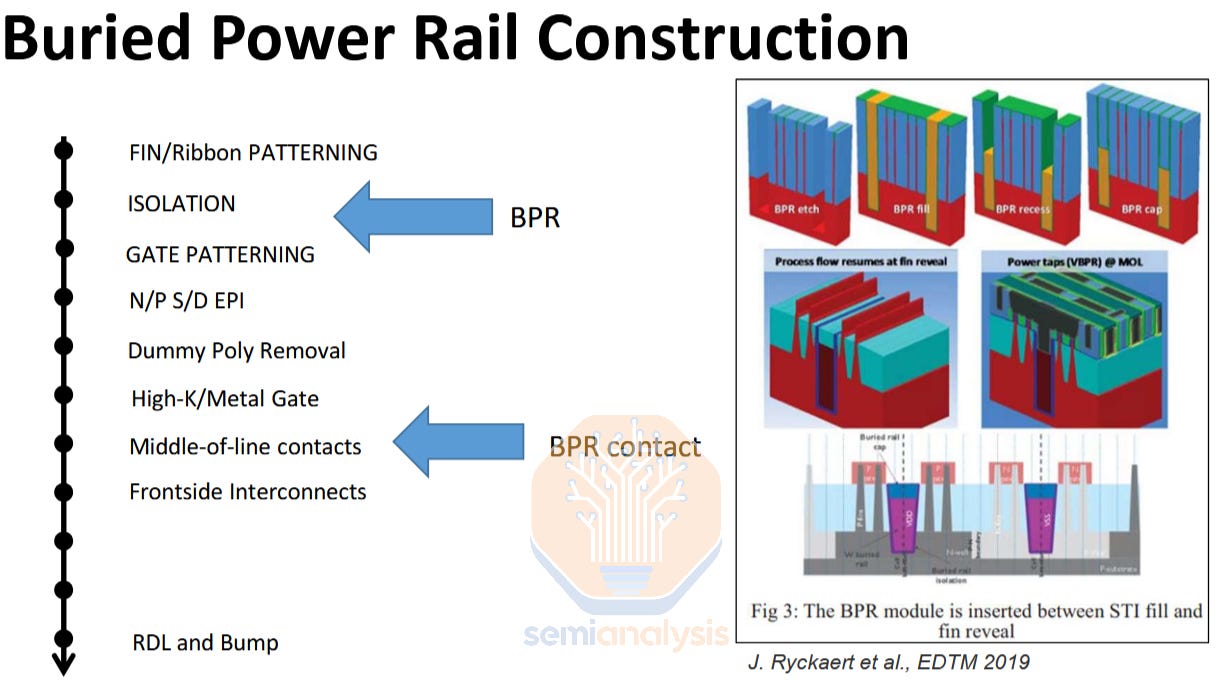
埋入式电源轨需要在前端加工步骤中使用金属。资料来源:英特尔
对齐连接埋入式导轨的初始背面特征是另一项挑战。键合到支撑晶圆上会导致变形,必须进行校正,这使得键合后光刻变得更加困难。ASML和其他公司在这方面取得了显著进展,键合后覆盖能力足以满足BPR方案的要求,但对于更复杂的选项(如背面触点)来说,还处于规格的边缘。
来源:imec
二、电源通孔PowerVia
PowerVia是英特尔的背面电源解决方案。它在两个主要方面改进了BPR:
1.电源轨移至芯片背面,避免了BPR的污染风险。
2.由于消除了晶圆正面的电源布线,因此单元扩展性更好。
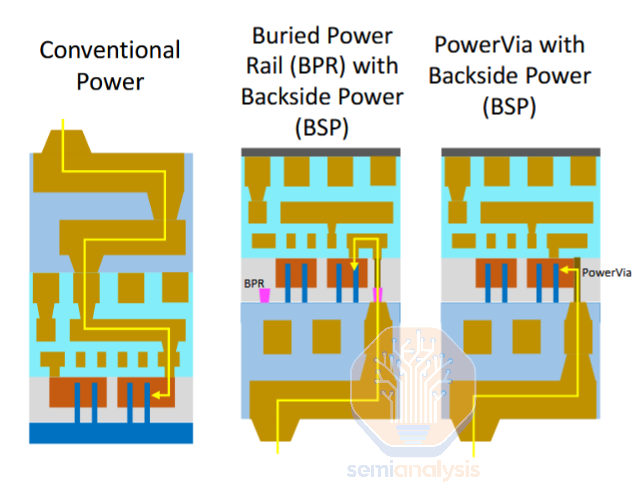
PowerVia连接到晶体管触点的一侧,避免了正面的电源布线。资料来源:英特尔
PowerVia是BPR概念的巧妙演变。在前端处理过程中,PowerVia完全跳过了电源轨。除了避免在晶体管之前沉积金属的污染风险外,它还省去了昂贵的对准关键工艺步骤(将BPR对准晶体管通道)。在千兆级制造规模中,像这样的单个关键层的模具成本可能高达数亿美元。
与传统的全正面方案相比,唯一增加的步骤是在晶体管触点之后建造一个又高又细的PowerVia。该通孔从触点深入到大块晶圆基板。完成正面后,晶圆将被翻转、键合和减薄。由于通孔深入晶片背面,因此在减薄过程中可以露出来,而不会有损坏晶体管的风险。这种巧妙的“自对准”方法大大简化了必须与PowerVia对准的背面图案(这种接触中的自对准实际上意味着对准要求大大放宽,即成本更低,产量更高)。
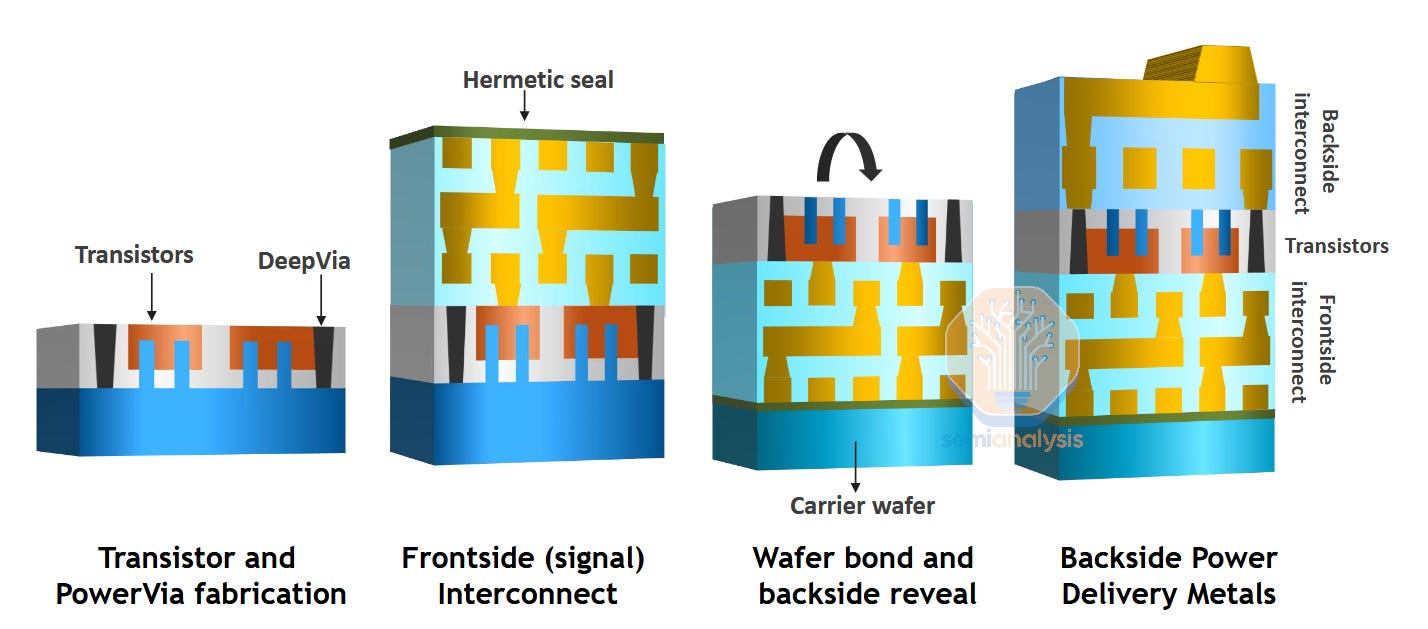
资料来源:英特尔
这种方法还具有缩放优势。BPR从晶体管触点的顶部通过一个过孔连接到晶体管,穿过正面的金属层,然后再通过另一个过孔到达BPR本身。这些低金属层是限制缩放的关键因素之一,因为它们需要一些最小的功能和非常拥挤的布线--通过它来布线电源,BPR几乎无法缓解这方面的问题。PowerVia则有所帮助。从晶体管触点向下直接布线到BSPDN意味着没有电源通过关键的正面金属层。这意味着这些层的间距可以放宽(降低成本),缩放可以更积极,信号线可以取代重新定位的电源线,或者三者的某种组合。
然而,仍有一些标准单元的缩放仍有待解决。PowerVia虽然比BPR薄,但仍然会增加单元的总高度。
三、直接背面触点
直接背面触点(DBC或BSC,代表背面触点)提供了一种消除功率对标准单元高度影响的方法。换句话说,在任何背面电源方案中,它们都能实现最大的扩展优势。这一理念是BPR和PowerVia的自然延伸——不是从触点顶部或侧面布线,而是从底部布线。
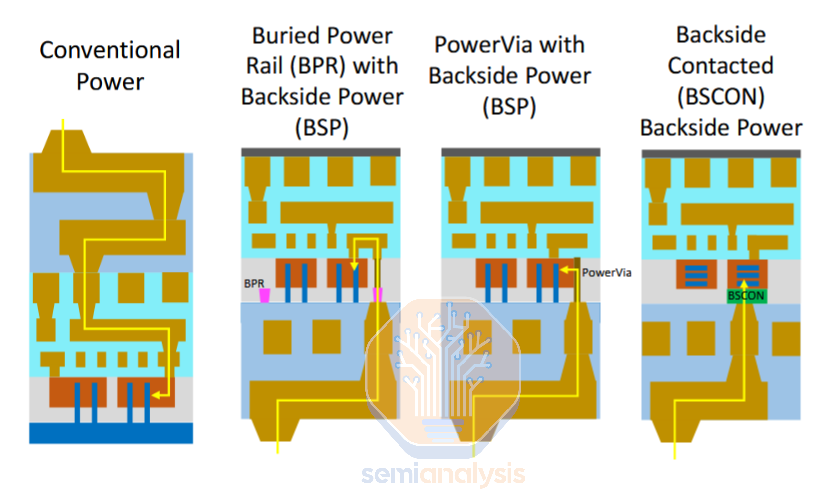
资料来源:英特尔
虽然想法很简单,但事实证明,背面触点是风险最高、回报最大的BSPDN选项。制造它们并不容易。主要的驱动因素是间距,即触点必须与其他特征对齐的距离。对于BPR和PowerVia,连接到背面特征的间距与单元的高度大致相同,现代尖端工艺的间距约为150~250nm。键合后光刻所需的覆盖层大于10nm,用于对第一个背面电源层进行图案化。这种叠加和大于150nm的间距很容易通过廉价的DUV扫描仪实现。
对于直接背面触点,要求则高得多。用于电源布线的触点形成于源极和漏极下方。源极到漏极的距离大致相当于接触式多晶硅间距(CPP),即栅极到栅极的距离。现代工艺的CPP是众所周知的,因此我们可以大致了解BS触点所需的间距——大约为50nm。这远远超出了单次ArF浸没曝光的分辨率,因此必须采用更昂贵的多重图案化方案或EUV。叠层技术也具有挑战性,因为其规格要求小于5nm。通常这对高端扫描仪来说不是问题,但在这里却极具挑战性,因为晶圆键合会产生高阶失真。
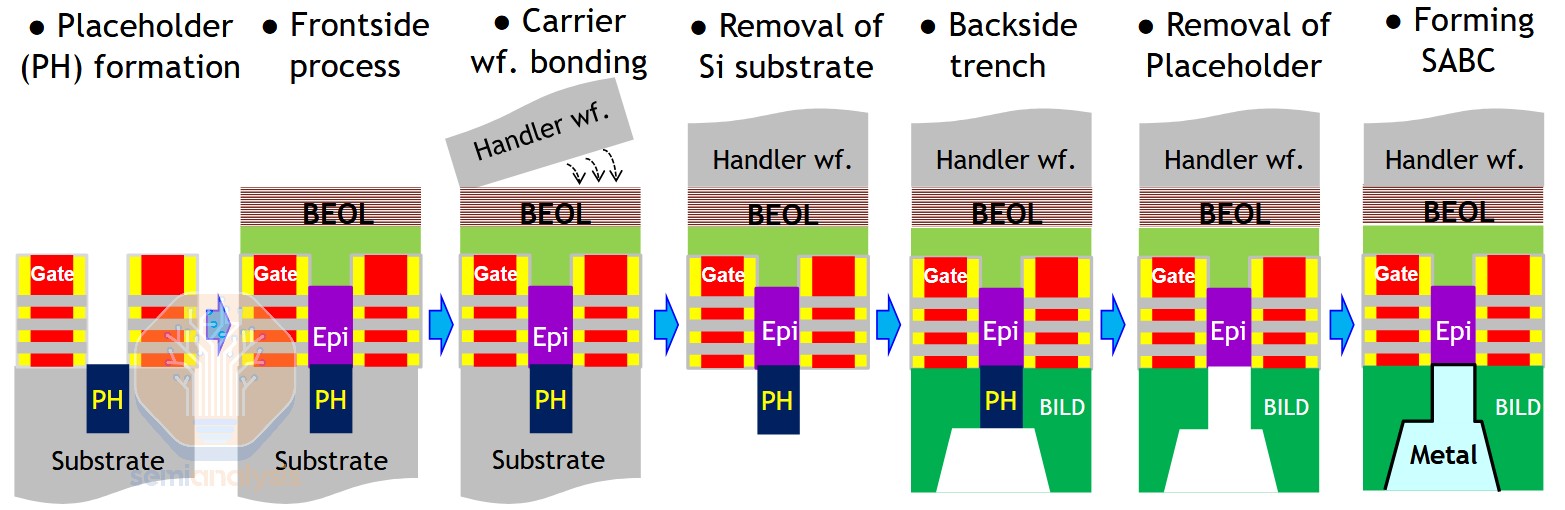
使用非导电占位符的自对准背面触电集成方案。资料来源:IBM+三星
另一个挑战是在FEOL中的金属使用,但现代的背面接触方案在这方面有巧妙的解决方法。与BPR一样,它们需要在晶体管之前制造一个额外的特征。但触点最初填充的是不导电的占位材料,而不是金属。一旦占位材料在减薄过程中显露出来(与PowerVia一样,这些特征是自对准的),就可以将它们蚀刻掉并用金属替代。这个技巧对BPR不适用,因为它们的纵横比很高,所以很难干净地蚀刻出占位材料。
尽管难以生产,但背面触点的好处是巨大的:理论上,一个6T的纯正面单元可缩小约25%,达到4.5T甚至4T。在实际应用中,与其缩小单元尺寸,还不如用信号线代替重新定位的电源线。这大大改善了布线,并且在芯片级仍能实现密度提升。线路电阻明显降低,功率节省约15%。时钟频率可提高5%以上。可靠性得到提高,因为正面和背面的导线都可以更大,从而降低电迁移的风险,并允许更快的开关或更大的电流。IMEC、谷歌和Cadence在今年VLSI大会上展示的一项研究发现,高功率(HP)库实现的效益最大,通常用于AI加速器等HPC(高性能计算)应用。
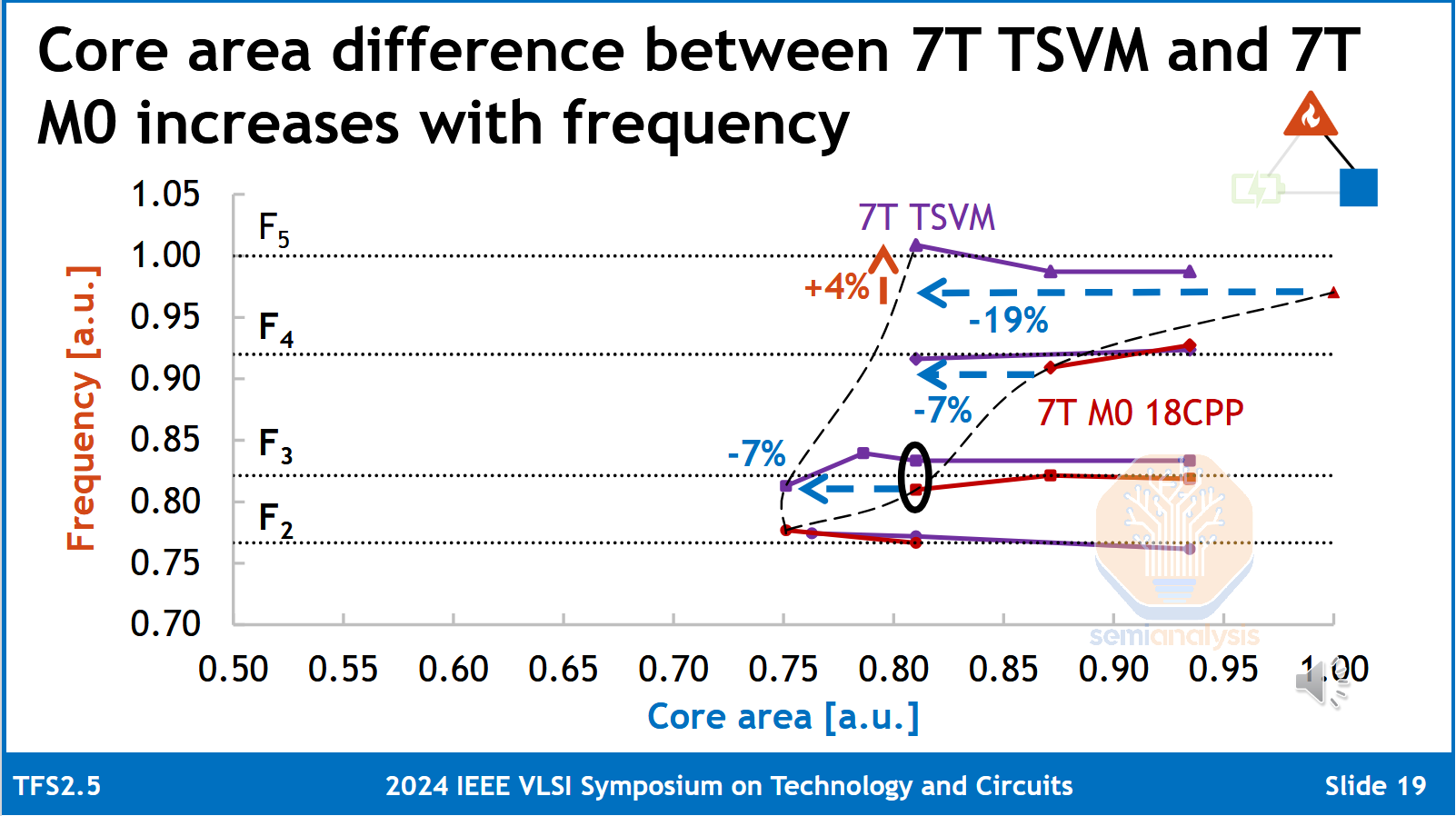
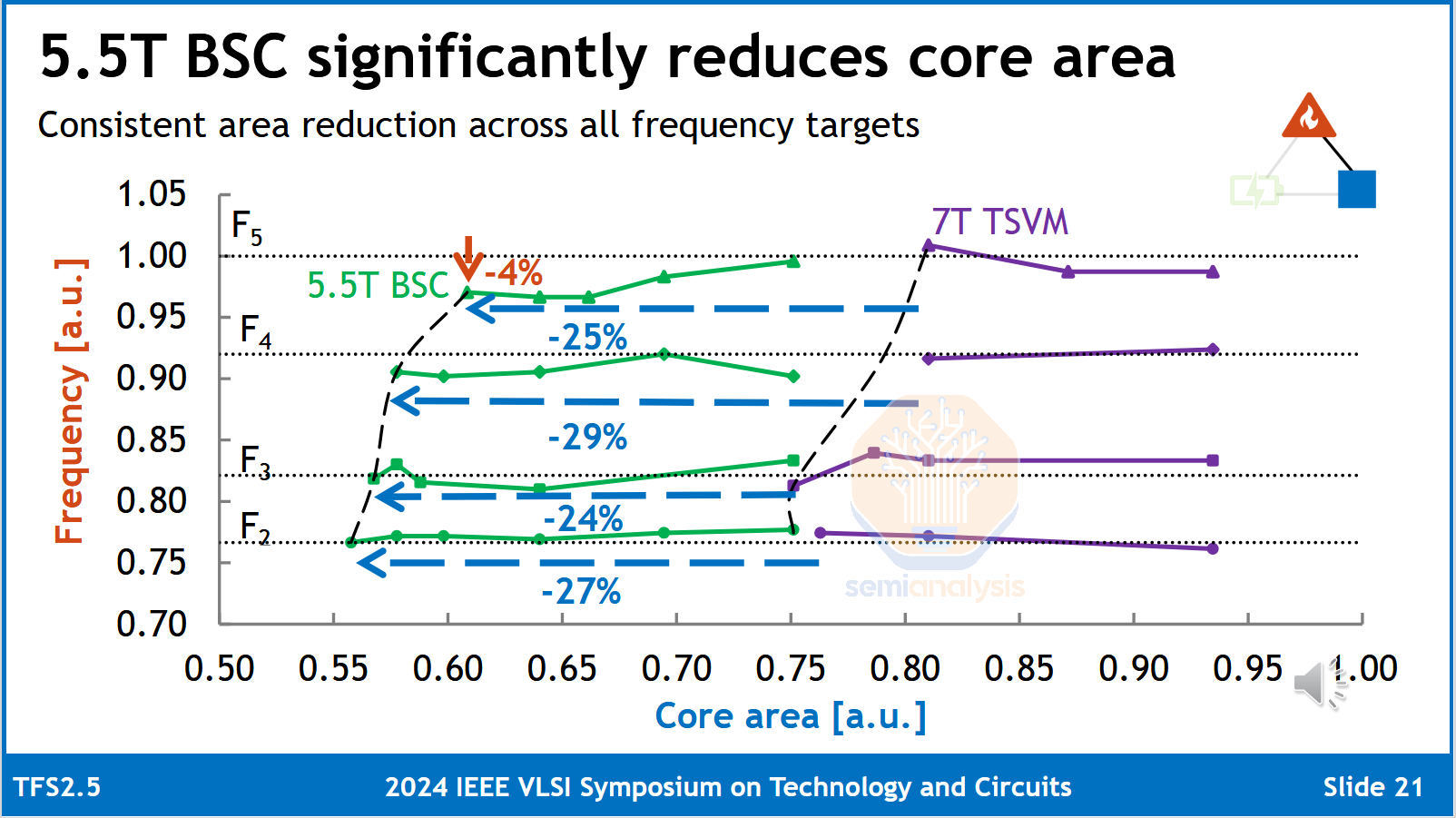
(1)BSPDN(7T TSVM = PowerVia,7T M0 18CPP = 仅正面)的缩放优势随时钟频率的增加而增加。芯片的速度更快,体积更小。(2)即使将PowerVia作为基线,背面触点也显示出显著的内核缩放优势 来源:IMEC、谷歌、Cadence
但是,这些优势并非毫无代价。总层数最多会增加20%。晶圆减薄虽然不会影响晶体管等有源元件,但会降低二极管等依赖厚硅的无源器件的性能,因此需要采取变通方法。所有背面工艺都必须与前端设备兼容:即它们必须不能需要会损坏晶体管的高温。
未来,背面将不仅仅局限于电源和全局时钟。信号和BEOL器件(如电容器)也有可能移动。对于堆叠晶体管(CFET)来说,这一点非常重要,因为底部器件的信号必须通过背面布线,才能充分实现缩放优势。1.4nm节点及以后的节点应该会开始增加背面的复杂性。
Rapidus、三星、英特尔、台积电的最新2nm路线图
在晶圆代工厂的路线图中,GAA和BSPDN在时间和架构方面的差异之大令人惊讶。
先从最新加入晶圆代工竞赛的公司说起:Rapidus是一家新兴的晶圆代工企业,其诞生源于日本在先进半导体制造领域重新获得平等地位的愿望。他们得到了日本政府的大量补贴,并从丰田、索尼等8家大型当地公司获得了额外资金。该公司的目标是在2025年4月开设一条2nm试验生产线,在2027年实现量产,并进一步发展到至少1.4nm节点。这是一家全新的公司,试图从2022年成立5年内实现逻辑前沿的大批量生产(HVM)。我们相信这将是一段非常艰难的旅程。
通过联合开发合作,Rapidus将获得IBM 2nm工艺技术的许可,并将其投入生产。该工艺尚未被大批量使用(IBM的服务器芯片是在旧的格芯节点和现在三星5nm节点上制造的)。该工艺强调小批量生产,以实现快速迭代和快速学习。这对于一家试图提升前沿逻辑的新兴公司来说也许是合理的,但他们是在用学习速度换取量产效率。他们的竞争对手使用大批量生产是有原因的。
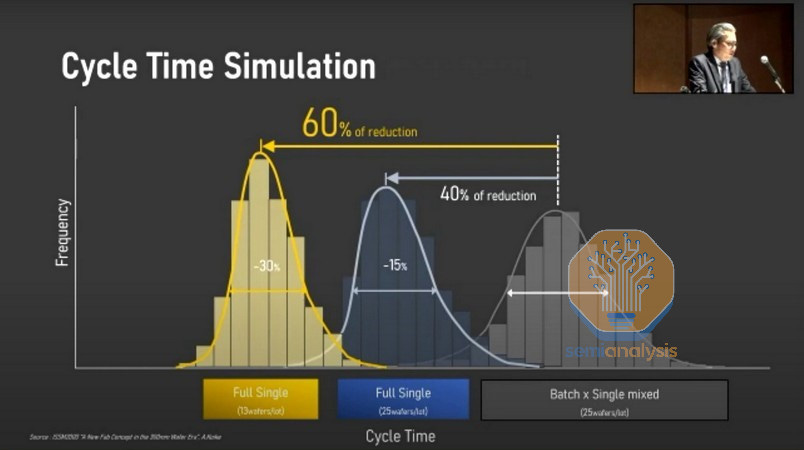
Rapidus声称,更快的周期时间和小批量加工的研发将帮助他们更快地扩展学习曲线。但这很可能会增加HVM的计量要求。资料来源:Rapidus
小批量生产可以缩短某些步骤的处理时间,但这也大大增加了计量需求。对于大批量生产来说,通常是在一个晶圆上进行计量,并假定同时加工的其他24个以上晶圆也会得到类似的结果。小批量生产实际上意味着每个晶圆都是“特殊的雪花”,需要单独计量。增加的计量负担应该超过小批量的优势。
他们的商业主张也值得怀疑。面对巨无霸台积电、工艺上有竞争力但财务面临挑战的英特尔,以及集整个财阀(和国家)的精力和财力于一身的三星,他们的市场地位在哪里?是什么促使客户将IP转移到月产能仅为2.5万片(而台积电在HVM最初几年的月产能通常在10万片以上)的新工艺上?日本政府推动Rapidus的2nm逻辑工艺几乎没有国内需求。他们很难在性能或成本方面找到竞争优势。到目前为止,还没有大批量的客户与Rapidus签约——Tenstorrent已得到确认,IBM可能会对其大型机芯片上对其进行测试。
此外,他们的计划不包括背面供电。这在HPC应用中将是一个不利因素,因为在这些应用中,竞争对手的工艺会通过包含BSPDN提供更好的性能和密度。单晶圆批量工具的研发不容易转移到多晶圆批量工具上。
三星也面临“客户挑战”,但仍在雄心勃勃地推进计划。从技术上讲,他们早在2022年就率先在SF3E节点上量产GAA,但并未以任何有意义的方式实现产品化。因此,SF2更像是一个进化节点,而不是革命性的节点。三星即将推出的某个节点很可能会在堆栈中添加第4个纳米片,而在可预见的未来,其他大多数节点都将使用3个纳米片。SF2P将提供更高的速度,但密度略低于SF2。
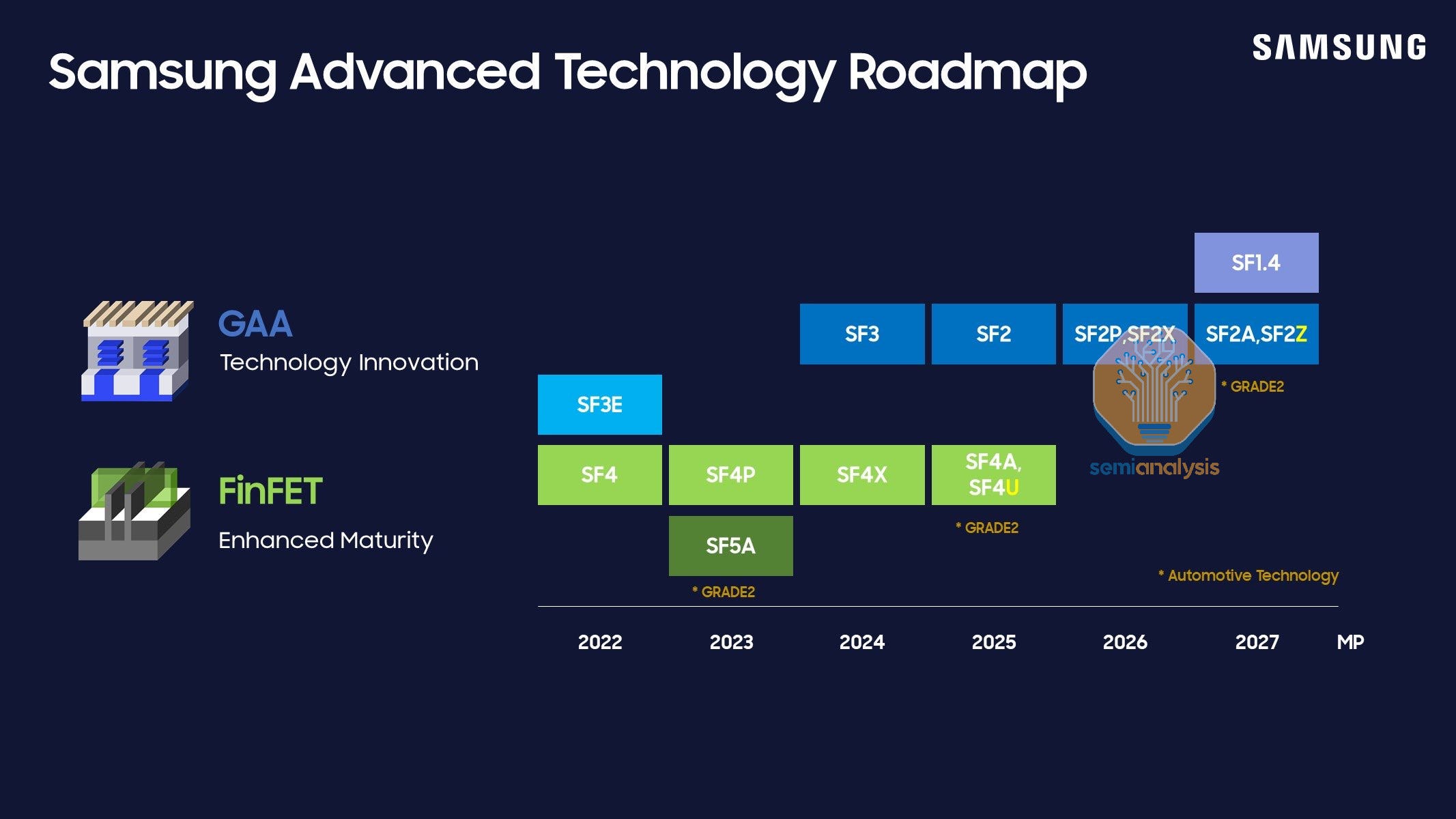
从SF2Z开始包括背面供电的三星逻辑计划 资料来源:三星
其计划的主要亮点是2027年在SF2Z节点上引入背面供电。在2024年6月举行的三星晶圆代工论坛上,透露该工艺将采用背面触点,将电源和全局时钟移至背面。该工艺的性能提高8%,功耗降低15%,面积减少7%,这些都是相对合理的说法。
SF1.4将缩放金属和栅极间距,并涉及纳米片的某种变化,而这只是预告。也有可能是二维槽型材料,但这需要非常激进的时间安排。
英特尔已经在加紧推进Intel 18A GAA + BSPDN节点。之前的Intel 20A工艺最近已被放弃,但这是出于财务原因,而非技术原因。最近有报告称,Intel 18A缺陷密度已步入正轨,由此看来,工艺技术也许是英特尔公司目前进展顺利的一个方面。
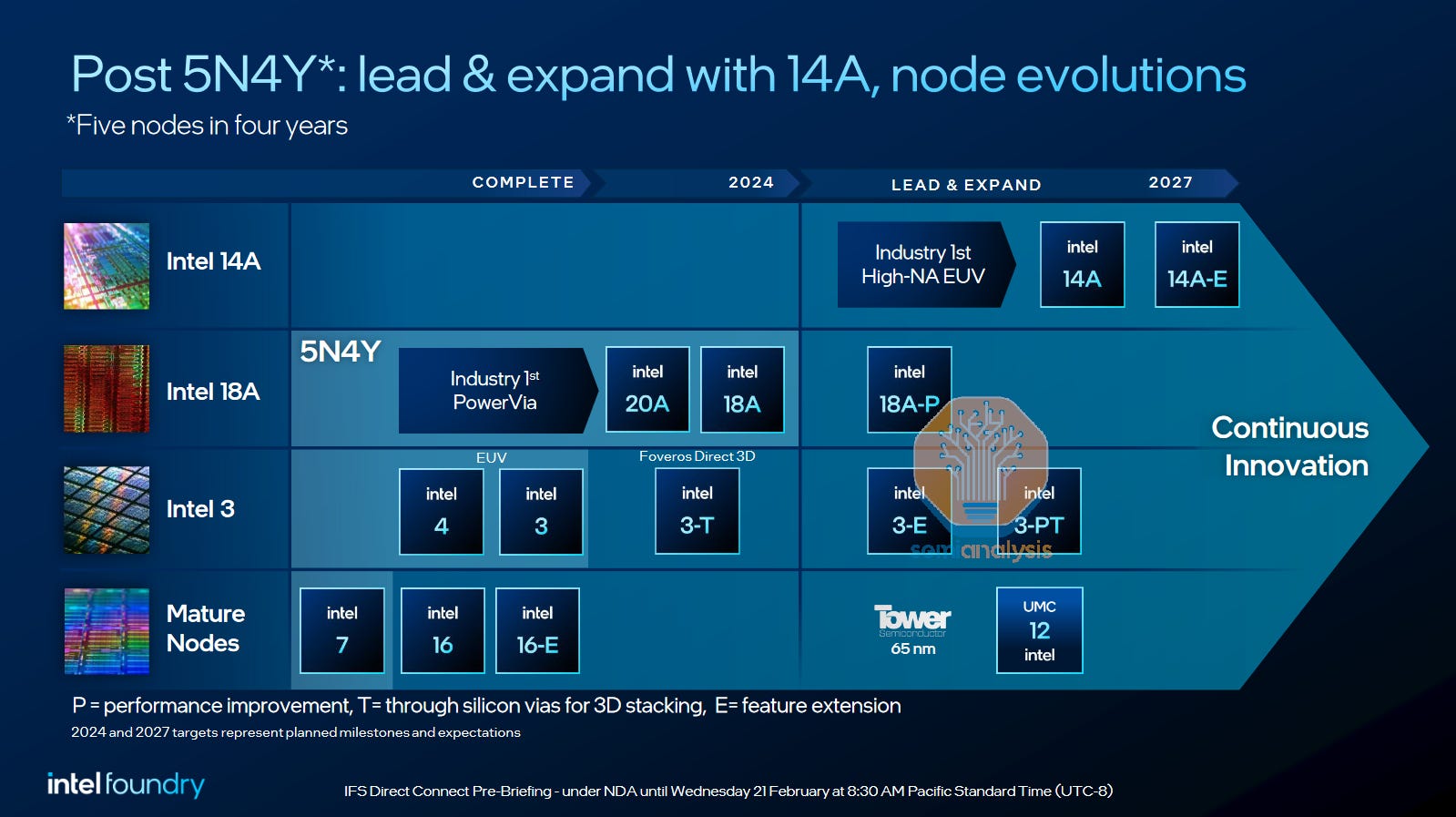
英特尔将率先向市场推出GAA+BSPDN流程。来源:英特尔
我们已经详细讨论过英特尔的计划和代工前景:
值得注意的是,英特尔正在使用PowerVia方案来处理背面电源。正如我们在上文详述的那样,这种方案应该更容易制造,但与直接背面触点相比,其缩放效益较低。
随着N2的推出,台积电继续稳步推进工艺节点的改进,这也推动其股价继续保持多年的复合涨幅。N2明年将实现大批量生产,采用台积电首个GAA架构,但不含BSPDN。变体N2P和N2X将在2026年提供温和的改进,并在今年下半年推出首个GAA +背面供电节点A16。与三星一样,台积电也选择采用背面接触方案直接进入BSPDN,而不是采用更简单、更保守的BPR或PowerVia方案。
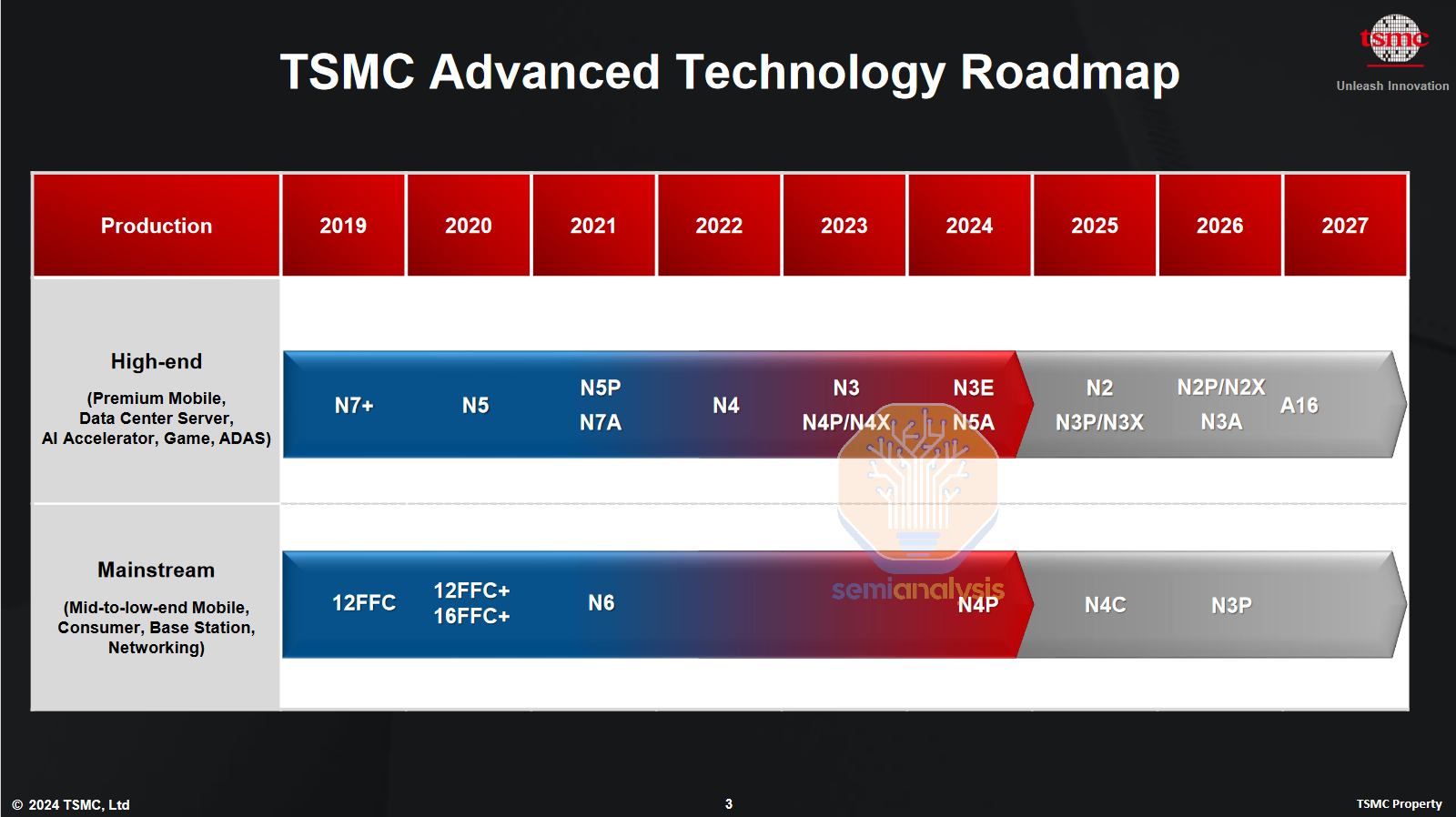
台积电将于2025年在N2上首次推出GAA,随后在A16上推出GAA + BSPDN。资料来源:台积电
在第一代产品中,其背面触点的实施似乎比较保守。宣称的7%~10%密度提升大约是理论上单元缩放可能实现的密度提升的一半。这样做可能是为了保持与N2的设计兼容性,FEOL可能保持不变,只需重新布线以利用背面供电网络。红外线衰减也会明显降低,功率可能提高20%。
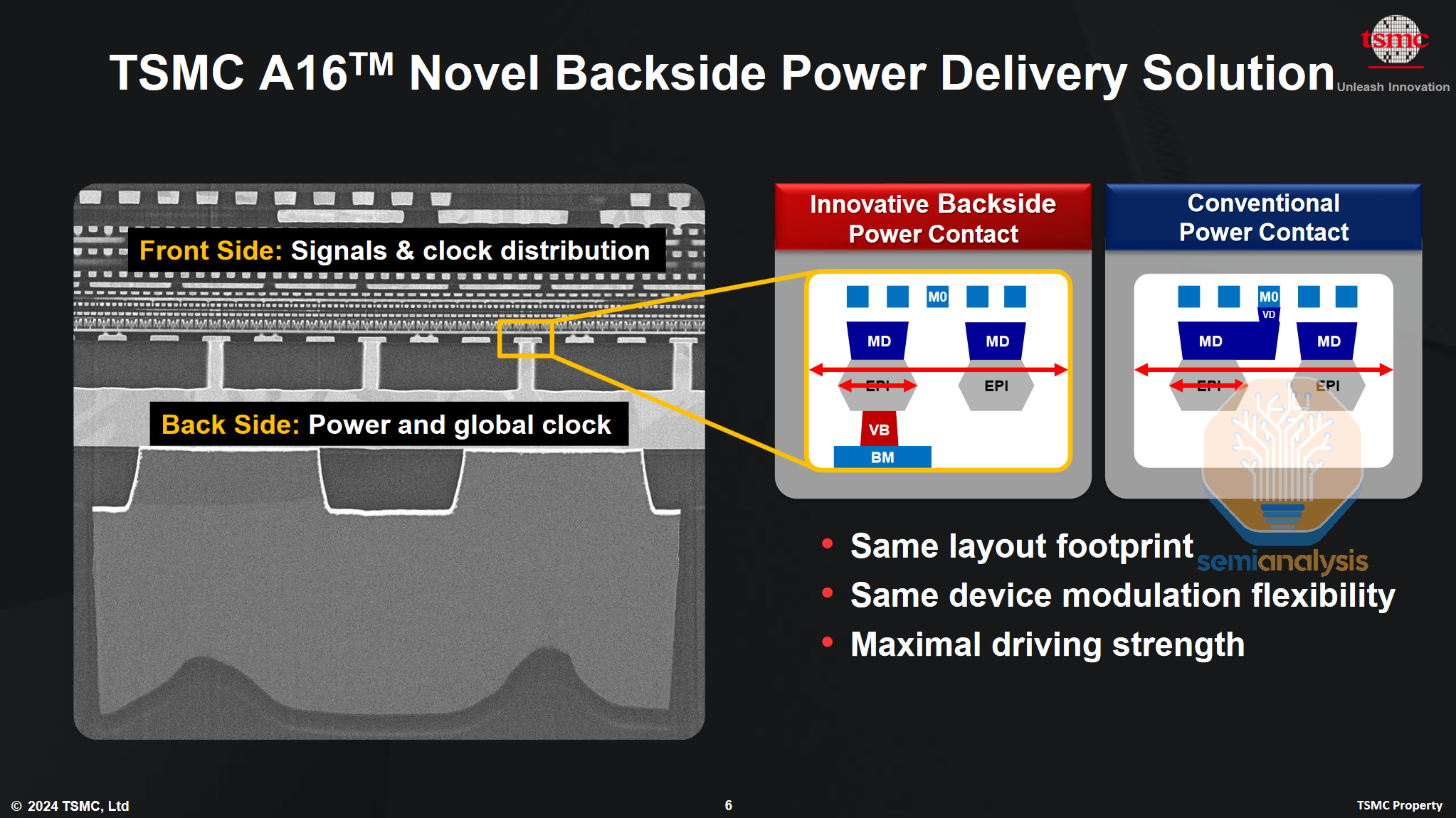
A16采用保守的缩放方式,在设计上更倾向于与N2兼容。资料来源:台积电
每家代工厂对GAA的实施都大同小异,区别在于它们在特征扩展方面有多激进。它们在性能、功耗和密度方面的说法大相径庭,在未经独立验证之前,应谨慎对待。
SRAM缩放:徒劳无功
SRAM是最快的存储器,也是最接近逻辑的存储器,因此SRAM的缩放是提高一代又一代芯片性能的关键驱动力。每个芯片设计人员都希望获得更多的SRAM(同时不影响芯片面积或成本)。然而,自5nm节点以来,SRAM位单元的缩放一直停滞不前,台积电的N3和N2节点几乎没有提供位单元缩放。大多数在其他地方实现缩减的缩放策略要么没有用,要么早就在SRAM单元中实现了。例如,单鳍晶体管终于在N3节点上应用于逻辑电路,但高密度SRAM从英特尔22nm(第一代FinFET工艺)开始就一直是单鳍的。由于位单元布线已经优化,背面供电带来的好处不大。
晶体管长度和宽度的减少是SRAM位单元缩放的最有力杠杆。与单鳍片器件相比,GAA晶体管的尺寸略小,因为晶体管通道长度和晶体管之间的间距可以减小。这意味着FinFET到GAA的转变中,位单元将获得一次性的缩放优势,但在后续节点中可能不会有太大的优势。
连接位单元中晶体管与电源和信号的触点也限制了位单元的缩放。它们必须足够大,以形成低电阻连接,并保持最小间距,避免相邻触点之间短路。随着材料工程技术的进步,这些触点的缩放速度也越来越慢。
SRAM外围与其他逻辑一样,仍然受益于现代DTCO(设计技术协同优化)和其他缩放技术。台积电声称,从N3E到N2,SRAM密度提高22%,而这主要来自于外围扩展。遗憾的是,在工作存储器和L2或L3高速缓存等关键应用中,外围仅占SRAM总面积的一小部分,因此这方面的优势并不明显。整体性能的提高(如果达到要求)将主要来自逻辑单元,而不是SRAM。
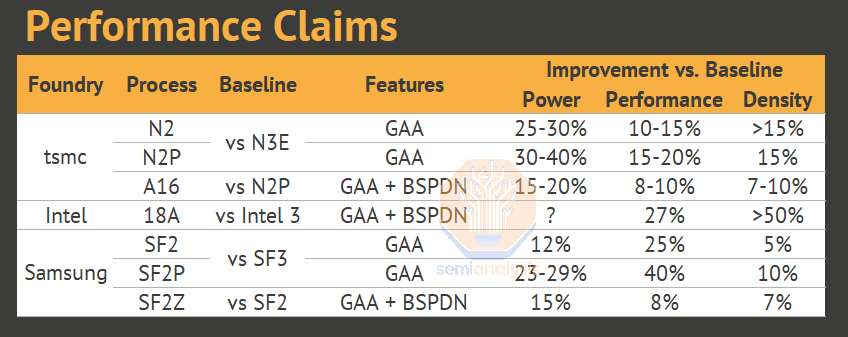
资料来源:台积电、英特尔、三星
三家大型代工厂真正大批量引入GAA将在2025年,Rapidus将于2027年引入。英特尔将在一年左右的时间内率先推出BSPDN,但尽管名为Intel 18A,其密度更接近3nm工艺。
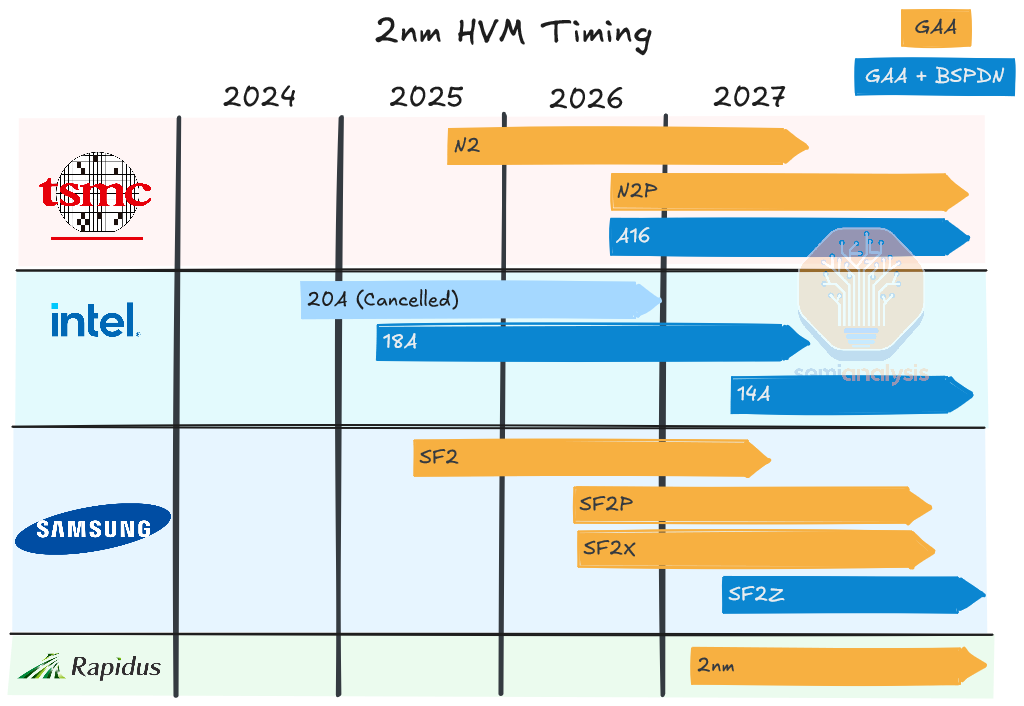
资料来源:台积电、英特尔、三星、Rapidus、SemiAnalysis
在今年12月份即将举办的国际电子元件会议(IEDM)上,台积电和英特尔将详细介绍2nm工艺,以争夺这一前沿领域的主导地位。
据称,台积电的研究人员将公布N2制造工艺,这是一种标称2nm工艺,专为AI、移动和HPC而设计。研究人员预计将报告,与2022年推出的N3(标称3nm)工艺相比,N2的速度可提高15%或功耗降低30%,芯片密度也可提高15%或更高。
英特尔工程师将提供有关RibbonFET(英特尔纳米片晶体管)的扩展细节。目前没有提及英特尔的具体制造工艺,但RibbonFET计划在Intel 20A工艺(即标称20埃或2nm工艺)中投入生产。英特尔似乎选择不推出任何基于Intel 20A的处理器产品,而是直接从3nm工艺转向Intel 18A工艺。
参考链接:https://www.semianalysis.com/p/clash-of-the-foundries
https://www.eenewseurope.com/en/intel-tsmc-to-detail-2nm-processes-at-iedm/
7、100亿美元估值被砍一半,贝恩资本放弃铠侠IPO计划

消息人士称,投资者迫使贝恩资本将其对日本铠侠的首次公开募股(IPO)估值削减近一半,导致这家美国公司放弃了这家存储芯片制造商10月份上市的计划。
近日有消息称,铠侠放弃了10月份IPO计划。铠侠于2018年被贝恩牵头的财团以2万亿日元(134亿美元)从东芝手中收购,当时名为东芝存储。
消息人士称,这一决定是在全球投资者希望这家芯片制造商的市值达到8000亿日元左右之后做出的,而贝恩的目标为1.5万亿日元。
估值差距使得贝恩资本退出对铠侠六年投资的努力变得复杂。消息人士称,这反映出投资者对存储芯片市场实力的担忧。
“鉴于NAND市场状况,今年上市似乎很难,尽管在本财年结束前有可能实现,”一位与铠侠会面的亚洲对冲基金的基金经理表示,他指的是铠侠专攻的存储芯片。
铠侠经历了多年的动荡,包括从丑闻缠身的东芝分拆,以及由于投资者SK海力士的反对而与合作伙伴西部数据的合并谈判陷入停滞。
存储芯片制造商受到智能手机和个人电脑需求低迷的打击,铠侠还面临来自韩国和美国竞争对手的激烈竞争。
Omdia高级分析师Akira Minamikawa表示,尽管今年由于人工智能(AI)的普及,NAND价格有所上涨,但价格上涨已趋于平稳。他表示,智能手机和个人电脑AI功能的实施预计将推动明年及以后的更换需求。
铠侠专注于NAND闪存,这是该公司在20世纪80年代发明的。相比之下,SK海力士也生产DRAM芯片,由于其用于AI芯片的高带宽存储器(HBM)需求旺盛,该公司的势头正在上升。
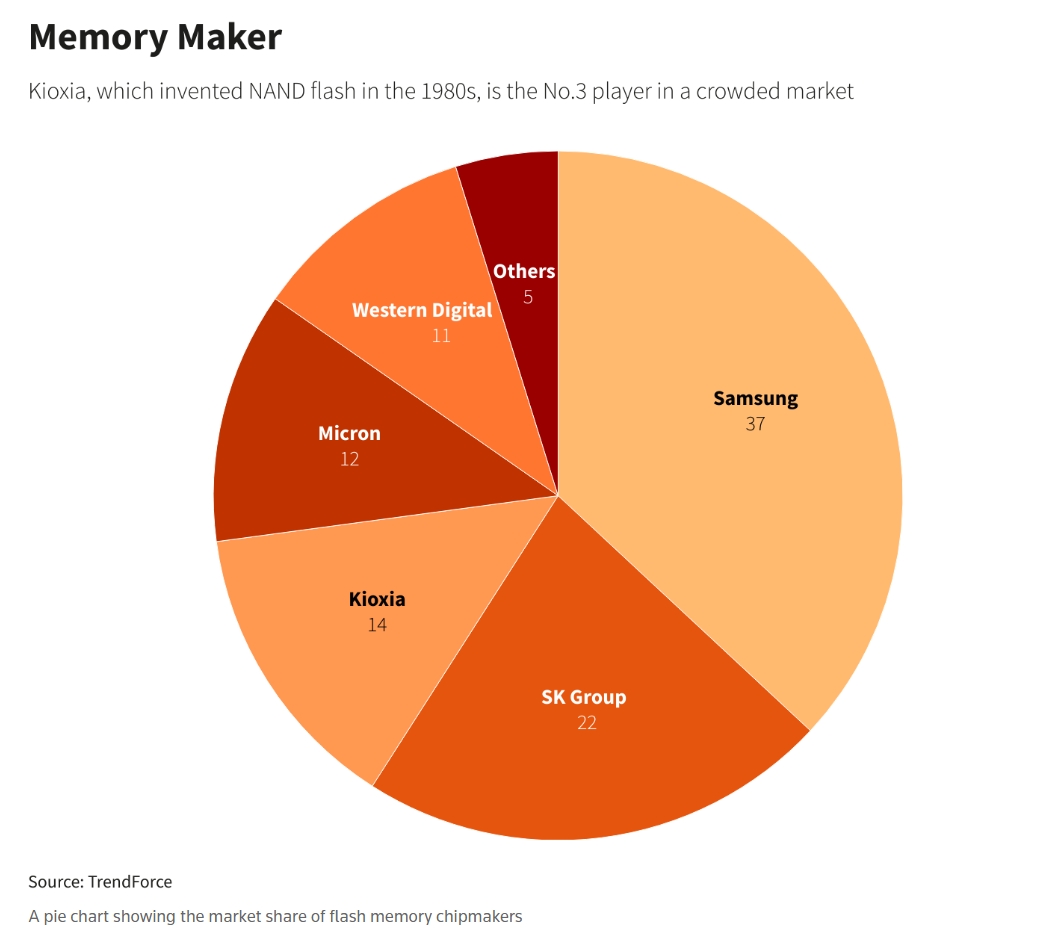
“我不想在NAND市场短期见顶时买入股票,”一位与铠侠会面的西方基金投资组合经理表示。
退出时机
日本股市在意外加息和首相更替后一直波动不定。日经基准指数(.N225)今年迄今上涨8%。
铠侠上市的尝试受到密切关注,这视为日本收购公司的一个试验案例,因为越来越多的公司正在出售非核心资产或进行私有化。
麦格理资本证券日本研究主管Damian Thong表示:“私募股权通常不会收购半导体公司,因为资本需求很高,而且考虑到行业周期,很难把握退出时机。”
日本政府希望重振其曾经强大的半导体产业,已承诺向铠侠和西部数据提供高达2429亿日元的补贴,以扩大其在三重县和岩手县的生产。
一位政府消息人士表示,铠侠之所以重要,是因为它位于日本,并且是AI存储芯片的来源。
Damian Thong表示:“首先让铠侠以较低的估值进行IPO,然后在市场重新估值时发现其真实价值,这是合理的。”