
近日,清华大学医学院院长、讲席教授,北京清华长庚医院眼科中心、北京视觉科学与转化医学研究中心(BERI)知名专家黄天荫与眼科中心、BERI长聘副教授王亚星,以及多单位专家团队,基于亚洲人数据集,共同发表了一项关于基础模型(Foundation Model)泛化能力的重要研究。
研究结果表明,基础模型与传统模型在泛化能力上面临相似的挑战,尤其是在数据多样化上存在局限性。研究进一步指出,在当前医疗基础模型的开发中,确保数据来源的多样性以及推动全球范围的研究协作是应对这一挑战的关键。
近年来,基础模型为医学人工智能的开发提供了新路径。传统医学人工智能模型构建通常面临数据收集量大、标注成本高的难题,而基础模型在大量无标注数据上进行预训练,可微调后适用于各类下游任务,无需从头训练。此前发表在《自然》(Nature)上的RETFound是此类模型代表,然而,这类基础模型是否能够真正适用于其他人口群体仍不明确。
该研究基于亚洲人群数据,从青光眼诊断、冠心病诊断,以及三年内脑卒中风险预测三项任务出发,研究了基础模型在不同群体中的适用性。研究团队选取基于大规模视网膜图像预训练的RETFound基础模型和传统的Vision Transformer模型(在ImageNet上进行预训练)进行比较,以评估其在亚洲数据上的表现(如下图所示)。
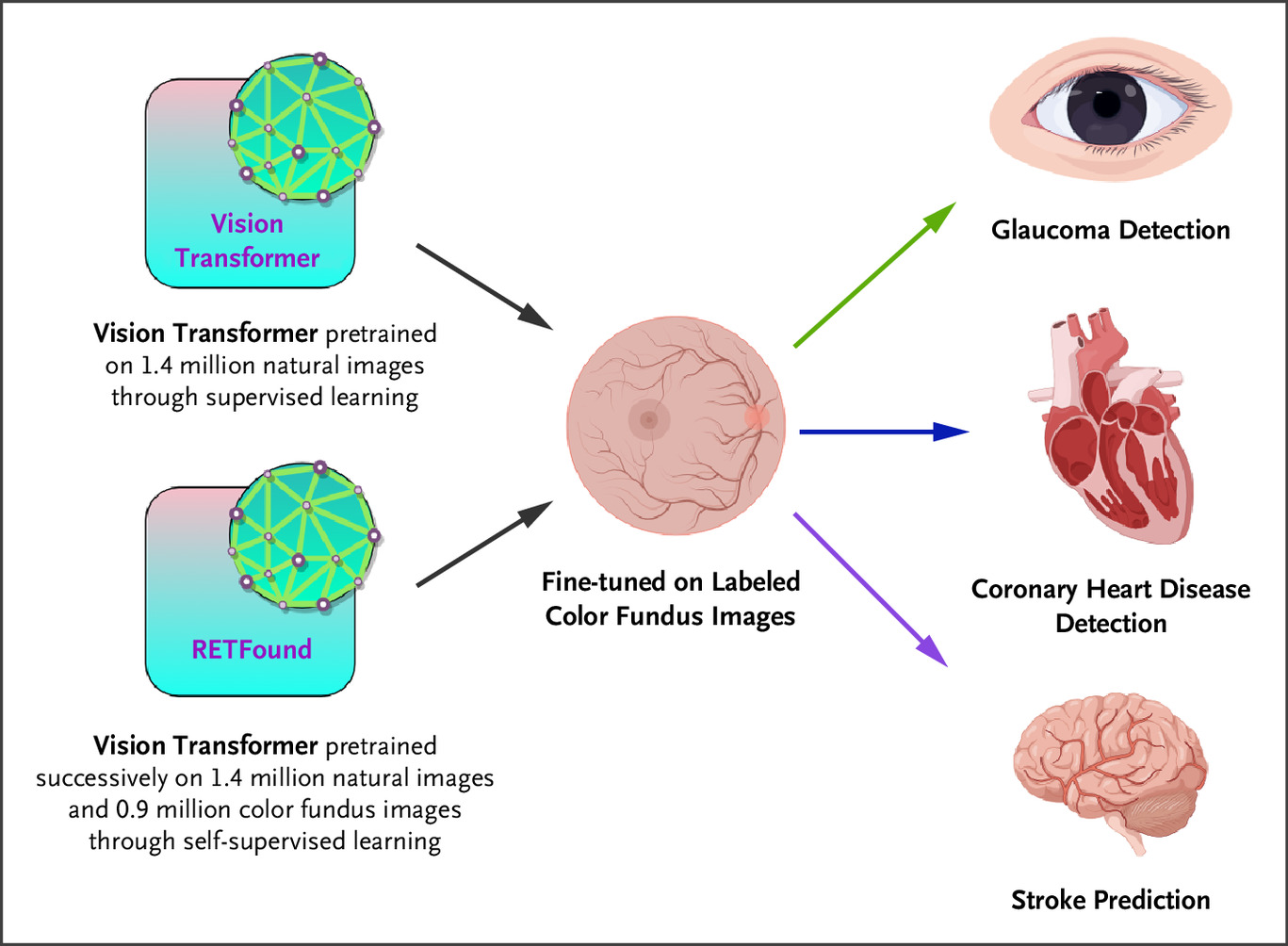
原理示意
结果显示,当使用完整数据集微调时,RETFound并未在性能上超越传统Vision Transformer。无论是在青光眼诊断、冠心病诊断还是中风风险预测中,两者的表现差异均无统计学显著性(P≥0.2)。在仅使用不超过完整数据集25%的数据进行微调时,RETFound具有微弱优势,AUC最高提升0.03,但同样无统计学显著性。
该研究进一步表明,尽管RETFound模型整体潜力较强,若要在特定人群与场景下实现理想效果,仍需更丰富、多元的训练数据支持。医学基础模型若未能在更加多样化的数据集上进行训练并在各种临床环境中进行测试,其对不同人口群体和临床情境的泛化性和适用性将受到显著限制。
该研究强调了在全球范围内加强医学基础模型合作研究的重要性,通过引入更加多元的数据集来提升模型的普适性和公平性,有助于医学基础模型在各类医疗场景中发挥更大价值,为全球医疗服务的智能化和精准化提供有力支持。
近日,相关研究成果以“基础模型在应用于不同的人群和环境时的泛化能力如何?”(How Generalizable Are Foundation Models When Applied to Different Demographic Groups and Settings?)为题,发表在《新英格兰医学杂志—人工智能》(NEJM AI)上。
王亚星与北京航空航天大学教授王晓飞、新加坡国立大学教授覃宇宗为论文共同通讯作者,英国伦敦大学学院团队亦对本研究作出贡献。
文章来源:清华大学









