


• OSP论文链接:
https://arxiv.org/abs/2407.04049
• 项目主页:
占据网格预测
占据网格预测是自动驾驶领域的感知任务,它将三维空间分割成许多体素网格,并要求模型预测每一个体素网格的占据状态和语义信息,不仅能灵活地表征各种形状的障碍物,还能适用于动态场景。目前大多数占据网格预测方法主要基于 BEV 表征进行算法设计。因为 BEV 特征是均匀划分的二维网格,它们无法对不同区域进行区分性处理,导致模型在训练时无法专注于难以学习和关键的区域,同时在推理时也无法实现端到端地精准预测各个位置。OSP 利用稀疏点集表征,在保持模型能力的同时增强了训练和推理的灵活性,能端到端地输出任意位置占据状态信息。
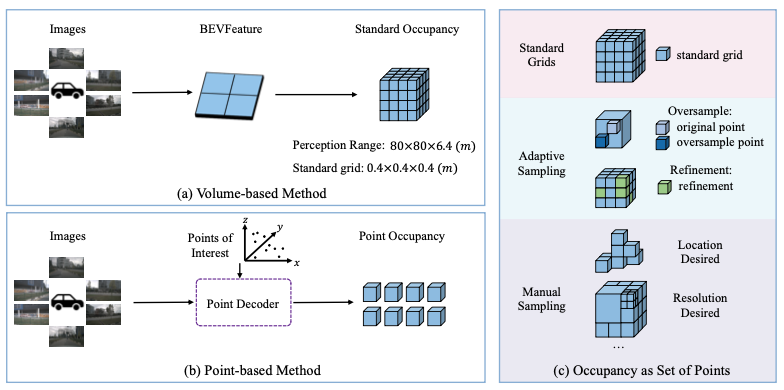
图1. OSP和BEV表征方法对比
算法框架
本文首先定义了 PoIs(Points of Interest)这一概念,这是一组用于表征三维场景的稀疏点,也是本文方法的核心。PoIs 可以表征空间中任意位置,包括普通的占据网格位置,或是需要受到额外关注的物体和区域。在模型的每一次前向推理中,当前 PoIs 的位置信息都会被编码并送入解码器。模型整体结构是基于变形器的编码器-解码器架构,包含骨干网络,位置编码器,点解码器和三维占据网格预测头。骨干网络负责从环视图像中提取多尺度图像特征;位置编码器负责对 PoIs 进行位置信息编码,并将其输入点解码器;点解码器负责将多尺度图像特征和位置编码信息进行交互和解码,进行注意力的计算,并将结果送入三维占据网格预测头;三维占据网格预测头负责预测 PoIs 对应的占据状态和语义信息。
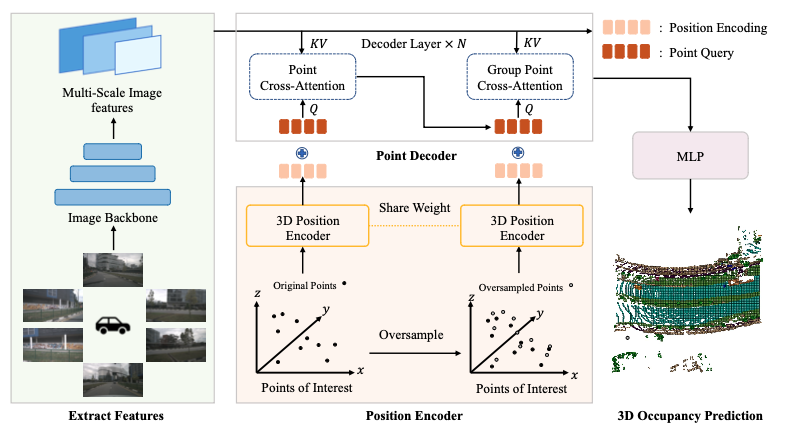
图2. OSP算法框架
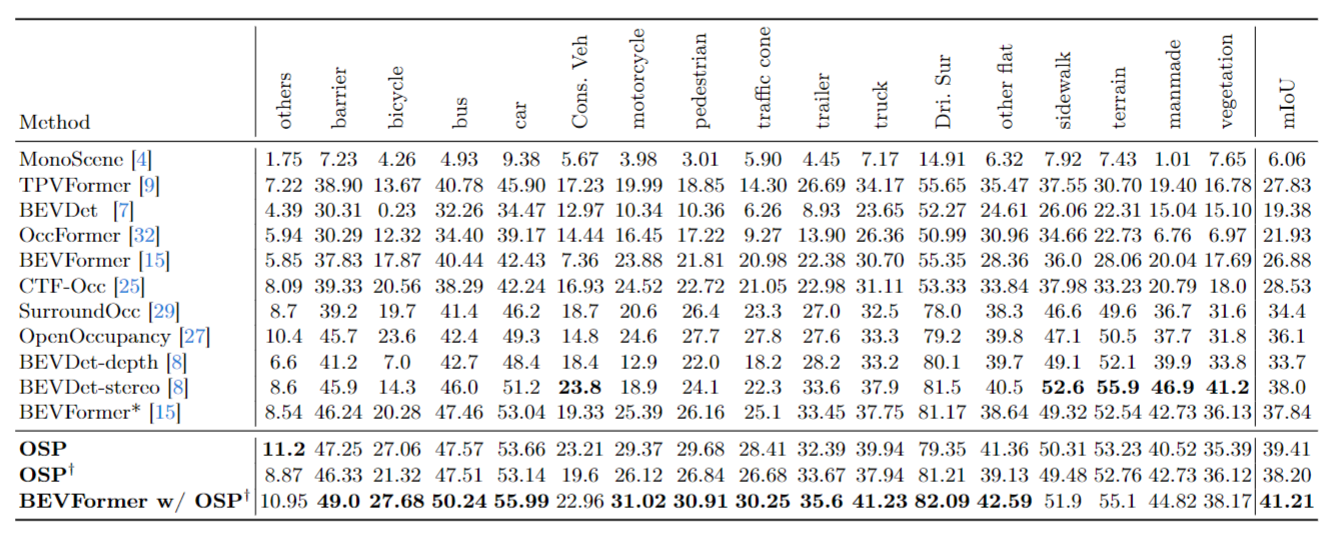
图3. OSP算法指标
本方法可用于增强 BEV 表征的方法,其增强流程如下图所示。对于一个现有的 BEV 表征方法,OSP 冻结其特征提取的骨干网络并训练 OSP 的解码器部分,这保证了同一个冻结的骨干网络能同时用于 BEV 表征方法和本方法,对于同一样本可以提取出相同的图像特征。训练完成后,对于给定的环视图像输入,二维的图像特征被冻结的骨干网络提取,并同时使用 BEV 表征的解码器和本章的点解码器进行解码,对于 BEV 表征的稠密的预测结果,本方法可以自适应的选取置信度较低的位置作为 PoIs 并生成稀疏的点预测结果,通过将稠密输出和稀疏的点预测输出加权求和得到增强后的结果。
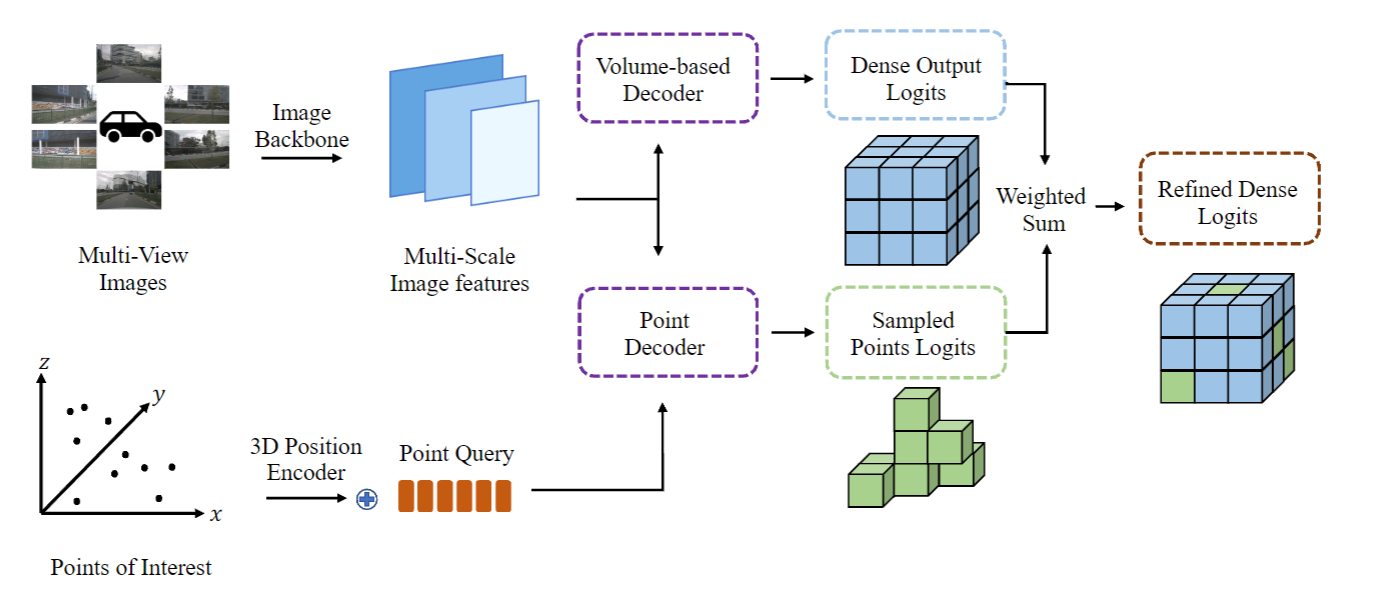
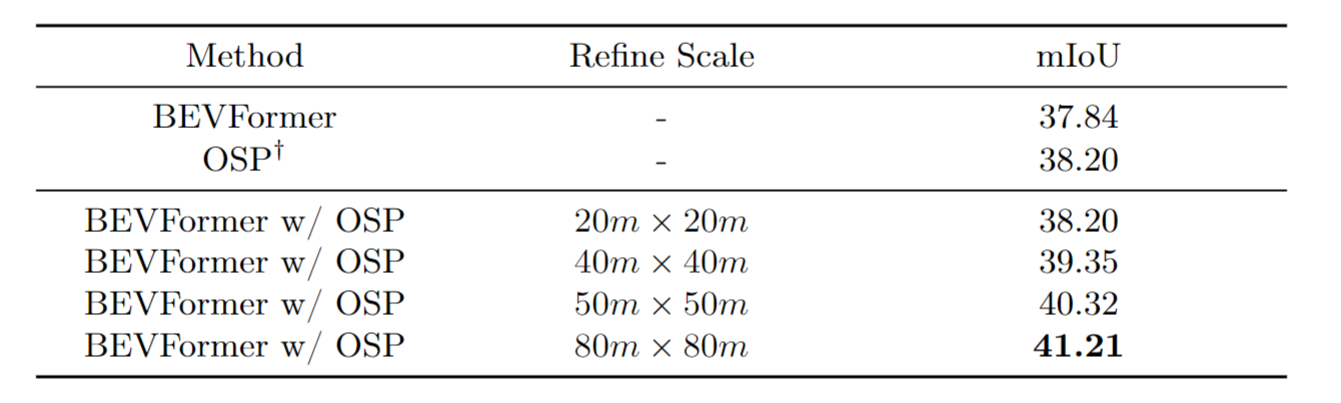
图4. OSP算法用于增强BEV表征方法
可视化
OSP 接受环视6V图像作为输入,可视化中从上至下从左至右分别是前左、前视、前右、后左、后视、后右的图片。OSP 预测以自车为中心长宽80米范围内的占据网格状态信息,可视化为俯瞰视角下的预测结果,期间不同的颜色代表了不同种类。
总结与展望
本方法为三维占据网格预测提供了一种全新的思路,在性能和灵活性上都有优越性。本方法利用稀疏点集的位置信息和多尺度图像特征对占据网格进行预测,平均交并比(mIoU)超过了基于 BEV 表征的方法;得益于自定义稀疏点集(PoIs)的高度灵活性,本方法可以端到端地输出任意位置的状态信息,也可以用于增强 BEV 表征的方法。这为未来的研究和应用奠定了坚实的基础。








