在以人工智能(AI)为代表的新应用下,大算力时代拉开序幕,与芯片算力达到相同热度的话题是存储与互联。当模型变得越来越大时,AI服务器除CPU外还需要搭配GPU进行多线程数据处理,每个GPU都需要搭配先进的HBM、GDDR等存储器。在大量处理器、加速器、存储器一起工作时,跨芯片、跨系统、跨节点的数据流动变得常见,彼此之间的互联效率变得重要,适应AI时代发展的标准规范也就变得不可或缺。近日,UCIe联盟、JEDEC固态技术协会、PCI-SIG标准组织、NVM Express组织的标准规范均有新的进展,其中大量涉及不同处理器之间的带宽、互联问题,其发布进一步夯实人工智能产业的技术底座。
HBM4:初步规范发布 传输速度翻倍
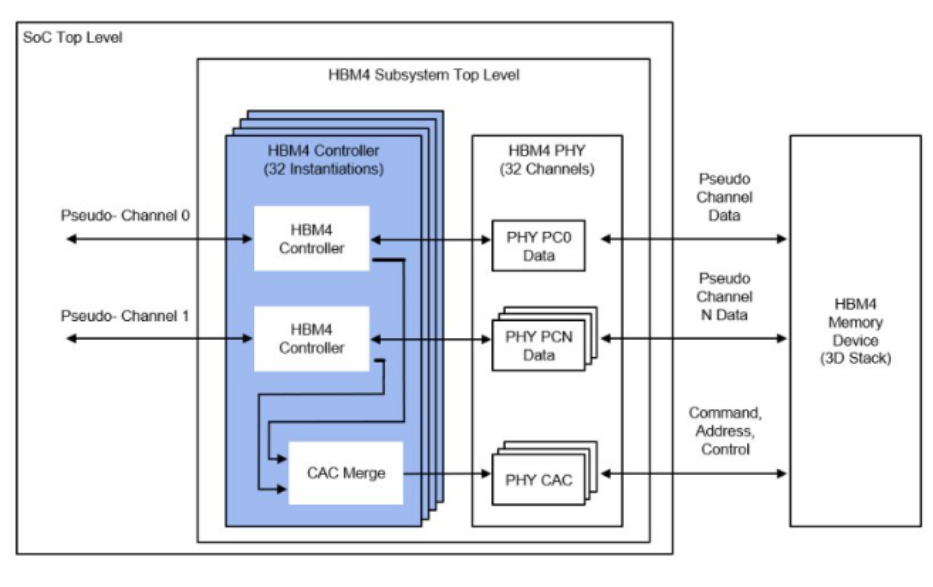
上月,JEDEC固态技术协会发布HBM4的初步规范。由于HBM的热卖,使得新规范的进展受到广泛关注。资料显示,HBM4将增加内存接口宽度,从每堆栈1024位增加到2048位。理论上,这可以实现传输速度的翻倍,从而显著提升数据处理能力。以英伟达H100为例,如果采用HBM4,理论上可以减少芯片数量而保持相同的性能,这将大大节省空间并降低成本。此外,HBM4还将进一步实现堆叠技术的提升,预计将从现有的8层/12层发展到16层垂直堆叠,这将在同一物理空间内容纳更多的内存单元,显著提高内存容量和带宽。
为了实现HBM4的高性能,各大存储巨头如SK海力士、三星等都在积极研发先进的封装技术,如混合键合等,将显著提升HBM4的可靠性和耐用性。例如,SK海力士在HBM 4中继续采用MR-MUF(批量回流模制底部填充)技术实现16层堆叠,作为替代方案而出现的混合键合技术预计由于 HBM 标准放宽也将缓慢引入。

SK海力士还计划将HBM4基础芯片上采用台积电的先进逻辑工艺,以支持更高的性能和定制化需求。今年早些时候,SK海力士和台积电宣布合作开发HBM4基模。台积电的N5工艺允许更多的集成逻辑和功能,互连间距从9微米缩小到6微米,这对片上集成至关重要。随着技术的进步,HBM4将不仅排列在SoC主芯片旁边,部分还会转向堆栈在SoC主芯片之上,这种设计将改变芯片的设计和制造方式,促进存储器与逻辑芯片的异构集成。
生成式AI的发展对算力有着极高要求,HBM4规范的发布将显著提升数据中心和超级计算机的算力水平,从而满足更复杂、更大规模的AI模型的训练和推理需求。而更高的算力和性能将使得AI应用更加普及和深入,不仅限于科研和高端应用领域,还将逐渐渗透到日常生活和工作的方方面面,如智能办公、自动驾驶、医疗诊断等。
UCIe2.0:简化芯粒设计 支持3D封装
8月7日,通用芯粒互连(UCIe)产业联盟发布2.0 规范。人工智能带给AI芯片最大的挑战之一就是需要处理大量数据,这要求各个组件包括CPU、GPU、加速器、内存和专用模块之间能够进行高效的通信。为了支持这些数据密集型任务,AI系统必须具备高带宽、低延迟、可扩展性和高能效的连接解决方案,芯片组件间的连接必须满足AI系统不断增长的带宽需求。UCIe的核心价值之一是定义了基于芯片的互连标准化框架,实现了不同供应商的芯片之间的无缝集成和通信。2.0 规范提升了系统级封装(SiP)的效率和性能,推动了芯片互连的标准化和互操作性,有利于为生成式AI提供更加强大的算力支持,同时降低开发成本和风险。

根据UCIe联盟释出的 UCIe 2.0 规范要点,首先是为任何具有多个芯粒的系统级封装结构的可管理性、调试和测试提供全面支持。这一改进确保了不同供应商的芯片能够无缝协同工作,形成统一的管理架构,从而简化了系统集成和故障排查流程,提高了系统的整体效率和可靠性。
在支持3D封装方面,UCIe 2.0规范着重优化了3D封装技术,相比传统的2D和2.5D封装,3D封装可缩短芯粒间的距离,实现了更高的集成密度和信号传输速度,从而提高了整体系统的性能。这对于需要处理大量数据的生成式AI应用来说至关重要,因为它能够提供更高的带宽密度和能效比。
对此,相关专家指出,UCIe旨在建立封装级别的互连。UCIe 2.0通过引入一系列创新功能,显著提升了系统级封装的效率和性能。为生成式AI提供了更加强大的算力支持。在标准化的芯片互连解决方案和优化的封装技术基础上,开发者可以更加高效地设计和集成系统,减少因兼容性和互操作性问题导致的开发时间和成本浪费。
PCIe7.0:草案持续发布 或将支持光信号传输
PCIe作为一种高速串行计算机扩展总线标准,PCI-SIG组织不断推出新的版本满足高性能计算、数据中心、人工智能等领域日益增长的数据传输需求。即便最新一代的PCIe 7.0标准最终敲定可能要到2025年,但相关参与者已经跃跃欲试。今年4月,PCIe 7.0标准已经走到了Draft 0.5版。新标准的框架已经得到确认。
按照传统,这次PCIe 7.0标准带宽将再度翻番。PCIe 7.0每pin达到128GT/s的数据传输速率。此外,通过x16配置,PCIe 7.0可以提供高达512 GB/s的双向带宽,这对于需要高效数据传输的生成式AI应用来说至关重要。当大模型达到万亿参数量时,要移动海量数据集,稳定、高带宽的互联至关重要,一旦数据传输成为瓶颈,芯片算力再高也都没有意义。
此外,随着AI模型的日益复杂化,需要更多的加速器来协同完成计算任务。PCIe 7.0能够连接这些加速器,提供所需的带宽和load-store结构需求,从而支持更复杂的AI模型训练和推理。同时,PCIe 7.0可使各部分基础设施能够高效地协同工作,处理大型、复杂的机器学习模型,提升整体计算效率。
依托光信号传输也是PCIe 7.0的一大亮点。PCIe 7.0规范可能会引入光信号传输技术,以满足数据中心日益提升的带宽需求。去年8月,PCI-SIG组建Optical Workgroup光学工作组,专注于光信号传输PCIe标准相关工作。业界普遍认为,光信号传输具有更高的带宽密度和更低的延迟,有助于提升数据中心的整体性能。
另外,在生态系统互操作性方面,PCIe 7.0规范的发布将推动相关生态系统的互操作性发展,促进不同组件之间的无缝连接和协同工作,推动生成式AI技术在各个领域的应用和普及。
NVMe2.1:优化存储设备性能 增强数据安全保护
在近日举行的全球存储会议FMS 2024上,NVM Express组织发布了 NVMe 2.1规范,包括3个新规范的发布,并更新修订了现有的8个规范。NVM Express组织希望新规范能更好地统一AI、云、客户端和企业领域的存储,优化存储设备的性能,提升数据存储与访问效率。生成式AI模型需要大量的数据进行训练和推理,高速的数据传输能够显著提升模型训练和推理的效率,从而缩短开发周期,加速AI应用的落地。
本次更新带来的NVMe新功能是支持在NVM子系统之间实时迁移PCIe NVMe控制器。这一功能可使存储设备之间的数据迁移更加灵活和高效。在生成式AI的应用场景中,这有助于实现数据的快速迁移和备份,保障数据的安全性和可用性。

NVMe 2.1还为固态硬盘提供了新的主机定向数据放置功能,这有助于简化生态系统集成,并向后兼容以前的NVMe规范。在生成式AI的应用场景中,这种功能使得数据可以更加灵活地分布在不同的存储设备上,提升系统的扩展性和灵活性。
NVMe 2.1还支持将部分主机处理任务offloading到NVMe存储设备。这有助于减轻主机的负担,提升整体系统的效率。在生成式AI的应用中,这种功能可以使得AI模型在训练和推理过程中更加高效地利用计算资源。
本次更新还增强了数据安全保护。NVMe 2.1规范提供了主机管理加密密钥的功能,并通过“每I/O密钥”(Key Per I/O)实现高度细粒度加密。这种加密方式能够确保生成式AI处理的数据在存储和传输过程中得到充分地保护,防止数据泄露和非法访问。NVMe 2.1还支持TLS 1.3、DH-HMAC-CHAP等安全协议,以及隐蔽处理后的介质验证等安全增强功能。这些功能进一步提升了存储系统的安全防护能力,为生成式AI的安全运行提供了保障。