
近日,深圳市半导体与集成电路产业联盟和与非网联合主办的“AI芯片与智算产业发展高峰论坛”和“云边无界AI技术分论坛”,在深圳会展中心(福田)隆重举行。会上,《2025年度国产AI芯片产业白皮书》正式发布,该白皮书全面梳理了国产AI芯片的技术演进、产业格局、落地挑战与未来趋势,为从业者提供前沿洞察与决策参考,爱芯元智作为重点企业入选。同期,爱芯元智AI推理引擎技术总监唐琦受邀发表《AI原生处理器:让大模型在终端跑起来》主题演讲,分享边端大模型趋势与爱芯元智的创新解决方案。

2025年边端大模型迎来爆发式增长,几乎每月都有新模型发布,从1月的DeepSeek,到2月的FireRedLLM、CosyVoice2,4月的Qwen3、SmolVLM2,5月的Qwen2.5-VL,6月的MiniCPM4,7月的SmolLM3,8月的InternVL3.5,再到9月的VoxCPM,模型迭代速度持续加快。
在这一背景下,NVR智能升级、NAS智能改造、离线实时翻译、语音克隆、家庭智能中枢、智能驾舱环境感知、具身智能机器人等行业场景,均提出对多模态大模型本地离线运行的强烈需求,推动算法精度与用户体验不断提升。
爱芯M.2算力卡:即插即用,高效赋能边端AI
面对边端大模型部署中“更换主控成本高、带宽占用大、影响核心业务稳定性”等痛点,爱芯元智推出基于AX8850的M.2 2242/2280标准接口算力卡,功耗<8w,以“即插即用”的方式为现有设备提供高效算力扩容。该方案支持从M.2卡扩展为PCIE卡,升级改造简便,显著降低部署门槛。

即插即用
基于AX8850的M.2 2242/2280标准接口算力卡
支持从M.2卡扩展为PCIE卡
目前,该算力卡已适配树莓派5、RK3588、Intel工控机等多种硬件平台,并配套推出MaixCAM-HAT、AX-M1、LLM8850等社区板卡,具备体积小、性能强、功耗低、性价比高等综合优势。


在核心芯片层面,爱芯元智推出搭载自研“爱芯通元AI处理器”的“爱芯元曦”系列AI芯片,专为边缘与端侧AI场景设计。该芯片采用“算子指令集+数据流DSA微架构”双核心理念,在性能、功耗与面积之间实现极致平衡。
其算子指令集支持包括Conv、Transformer、LSTM等在内的超百种AI算子,覆盖图像、视频、文本及多模态任务,并原生适配DeepSeek、Qwen、Llama等主流大模型架构。异构多核架构集成高效张量核、灵活向量核与高带宽数据引擎,支持4bit至32bit混合精度计算。配合高性能硬件多核调度器,可优化数据依赖,显著提升算力利用效率。成熟工具链生态提供从模型量化、编译优化到部署上线的全流程支持,兼容PyTorch、TensorFlow、ONNX等主流框架,大幅提升开发效率。
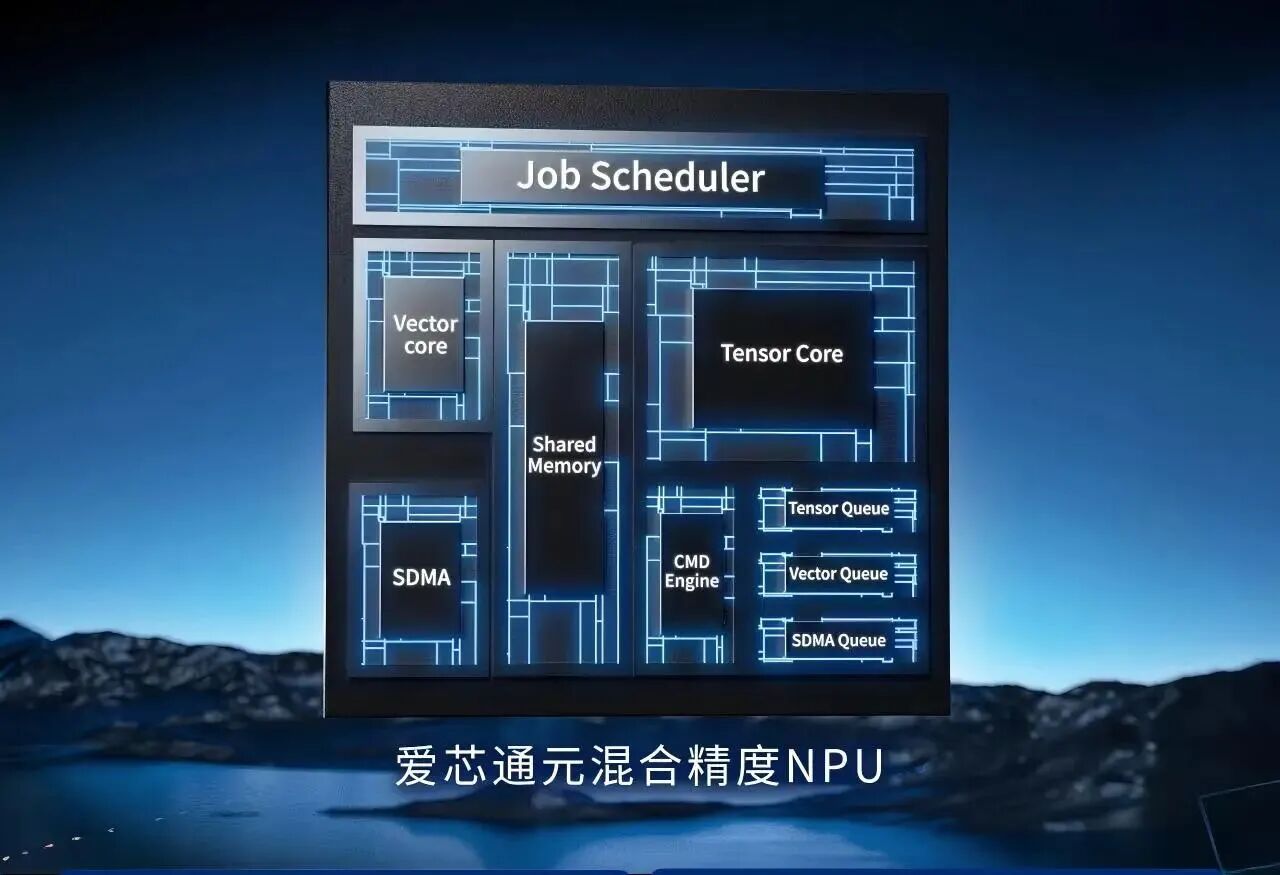
目前,爱芯元智AI处理器已完成高、中、低全算力布局并实现规模化量产,其能效比较传统GPGPU提升一个数量级,在以文搜图、通用检测、以图生文、AI Agent等应用中,为客户提供更具“智价比”的边端算力基建。
基于M.2算力卡与AI原生处理器,爱芯元智已在多个场景实现技术落地,包括NVR智能升级中的文搜大模型与Frigate NVR、NAS智能升级中的Immich智能相册,以及视频分析、StableDiffusion图像生成、视频超分与插帧、会议转录、语音克隆等丰富示例,展现出广泛的产品适用性与开源生态活力。
爱芯元智将持续以AI原生处理器与灵活算力解决方案,推动大模型在边端侧的高效、经济、环保部署,构建边端智能共同体,实现“普惠AI 造就美好生活”的使命。









