

不久前,边缘 AI 推理作为一种新奇的功能,可以轻松地由边缘设备嵌入的单个神经处理单元 (NPU) IP 加速器支持。然而,人们对此的期望已迅速提高。现在,我们希望嵌入式 AI 推理能够处理多个摄像头,复杂的场景分割,带有智能噪声抑制的语音识别,多个传感器之间的融合,以及现在非常大且复杂的生成式 AI 模型。只有在多核 AI 处理器上运行,这些应用程序才能为边缘产品提供满意的吞吐量。NPU IP 加速器已经可以满足这个需求,扩展到 8 个或更多的并行内核,并能够并行处理多个推理任务。但是,您应该如何对预期的 AI 推理工作负载进行分区,以最大限度地利用所有这些计算能力呢?本文讲述的就是这个主题。

资料来源:Ceva
利用 AI 推理并行性的六大路径
与所有并行性问题一样,我们首先从定义的 AI 推理目标的资源集开始,这些资源包括一些可用的加速器,具有本地 L1 缓存,共享 L2 缓存和 DDR 接口,每个缓存的缓冲区大小都已定义。接下来的任务是将应用程序要求的网络图映射到这种结构,优化总吞吐量和资源利用。
有一种明显的策略是处理需要分割成多个瓦片的大输入图像 – 通过输入地图划分,其中每个引擎被分配一个瓦片。在这里,多个引擎并行搜索输入地图,寻找相同的特性。相反,您可以通过输出地图划分 – 将同一瓦片并行输入多个引擎,并使用相同的模型但不同的权重在同一时间检测输入图像中的不同特性。
神经网络通常在子图中进行并行训练,如下方示例所示。资源分配时通常先优化广度,再优化深度,每次都优化到当前步骤。显然,这种方法不一定能在一次传递中找到全局最优处理方法,所以算法必须允许回溯以便探索改进之处。在这个例子中,3 个引擎能够提供的性能是只有一个引擎提供的性能的 230% 还多。 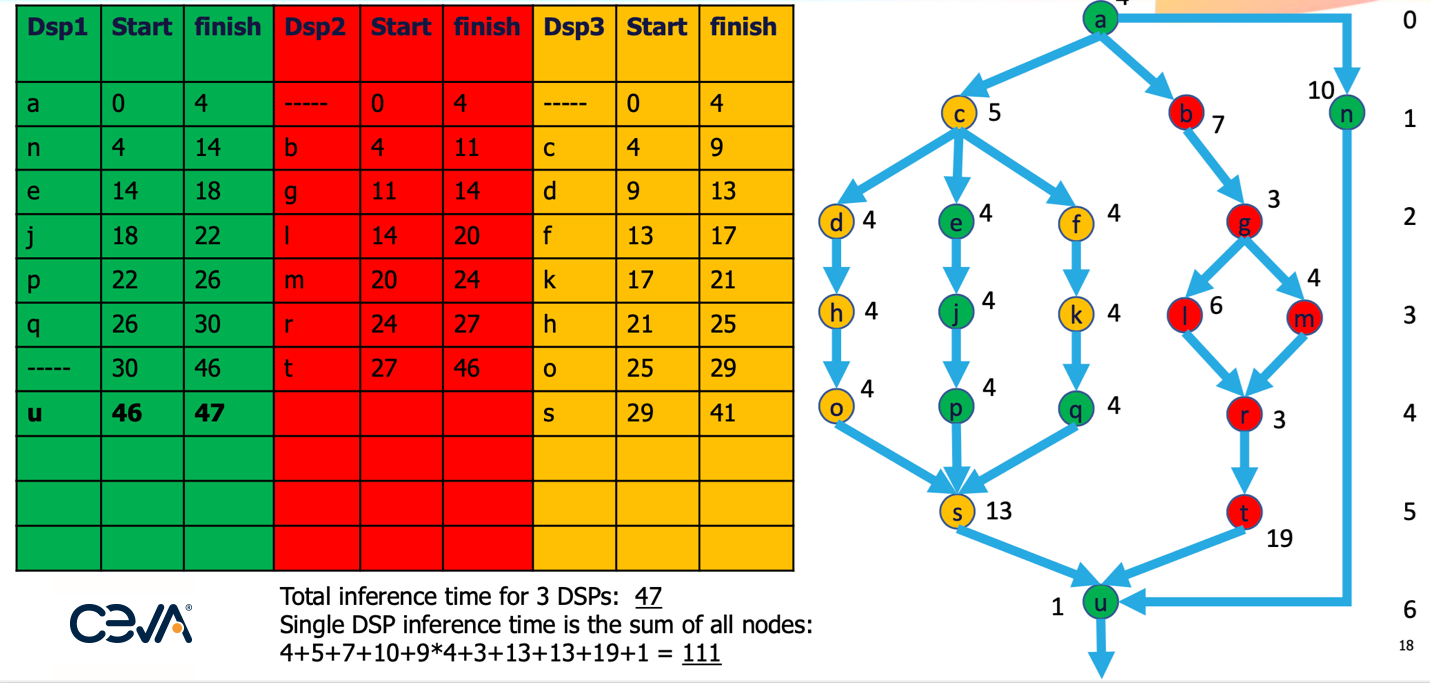
资料来源:Ceva
上图中的一些 AI 推理模型或子图可能显得很可并行化,也有其他一些 AI 推理模型或子图的长线程操作并不显得很可并行化,但仍然可以进行流水线处理,这在考虑通过网络执行流操作时可能会有益。另一个例子是深度神经网络 (DNN) 中的逐层处理。简单地组织每个图像的层操作以最小化每个引擎的上下文切换可以提高吞吐量,同时允许后续的流水线操作稍后但仍然比纯顺序处理要早地切入。基于转型器的生成性 AI 网络提供了另一个好例子,注意和规范化步骤的交替使得可以对连续的识别任务进行流水线处理。
批量分区也是一种方法,支持在多个引擎上运行同一个 AI 推理模型,每个引擎由一个独立的传感器“供食”。这可能支持一台监控设备的多个图像传感器。并且最后,您也可以通过让不同的引擎运行不同的模型进行分区。这个策略尤其有用于语义分割,例如,对于自动驾驶而言,部分引擎可能会检测车道标线。其他引擎可能处理开放(可驾驶)的空间分割,而另一部分可能会检测物体(行人和其他车辆)。
规划
在优化吞吐量和利用率方面有很多选择,但是您应该如何决定最佳的 AI 推理应用调优方法呢?这一架构规划步骤必须在模型编译和优化之前进行。这里,您需要在分区策略之间做权衡。例如,一个子图可能先并行,然后进行一系列的操作,有时最好仅通过流水线处理,而不是并行和流水线处理的组合。每种情况下的最佳选择将取决于图、缓冲区大小,以及上下文切换中的延迟。
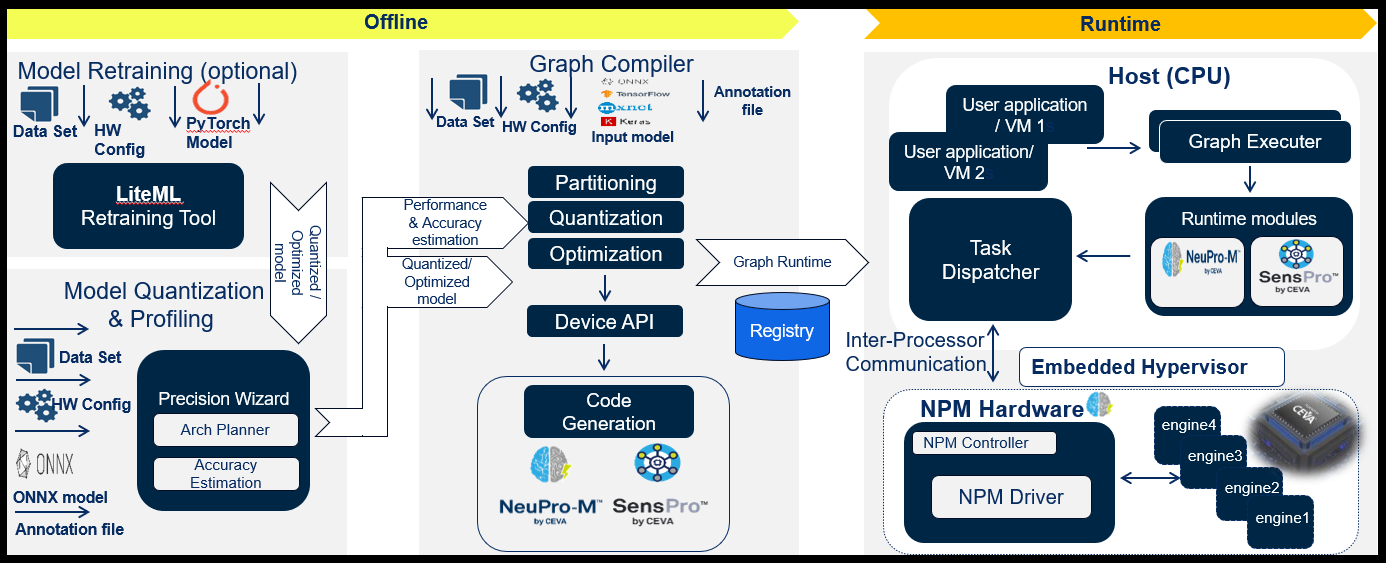
资料来源:Ceva
如果您一直努力研究如何在多核 NPU AI 推理子系统中尽可能好地优化您的 AI 工作负载,请查看我们的 NeuPro-M 平台,并向我们致电,交流有关边缘具有挑战性的 AI 推理工作负载的并行性的意见。









