以下内容来自2021智能存储论坛演讲实录《企业级SSD的新应用趋势探讨》。
近期,由陕西省西咸新区开发建设管理委员会、陕西省西安市科学技术局指导,陕西省西咸新区秦汉新城管理委员会、陕西省西咸新区工业和信息化局(科学技术局)主办,西安奥卡云数据科技有限公司、北京百易数字技术有限公司承办的“2021智能存储论坛暨奥卡云存储产品发布会”在西咸新区秦汉新城成功举办。此次会议旨在推动智能数据存储技术的交流与发展,促进存储与数据市场稳健成长,活动为期一天,吸引了线上线下逾千名业内人士关注。
作为国内企业级SSD产品领导企业,得瑞领新产品副总裁康雷就“企业级SSD的应用新趋势”这一主题积极思考并展开讨论,主要围绕以下几方面展开探讨:
· NAND and other emerging memories
· Computational Storage
· NVMe Updates
NAND and other emerging memories
首先,过去几年一些新介质在实用和新的场合都有了不同的进展。比较常见的是PCM -相变存储技术、MRAM-基于磁阻的技术和ReRAM。

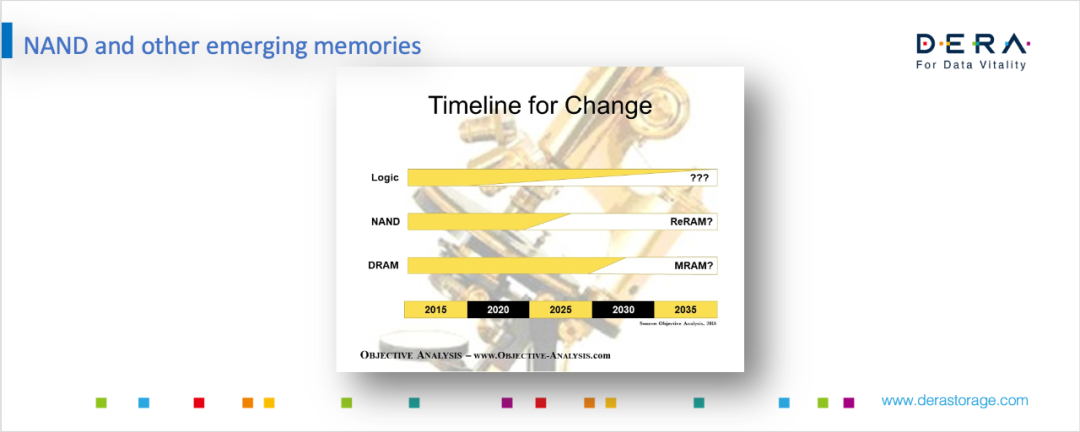
对于PCM技术,大家可能比较熟悉,比如英特尔3DX Point就是其中的一种;MRAM技术,目前有一些公司在开发,比如Everspin,并且与国内的一些公司也有合作;然后是ReRAM。下图是大概两年前一个相对乐观的预期。比如说2020~2025年之间ReRAM是否能替代Nand,目前来看还做不到这一点,另外,用MRAM来替代DRAM,目前看到的困难也比想的大。但相对来说,这是大家公认的趋势。
下图是不同存储介质从Memory到Storage类型的一个分布。左边是CPU SRAM,右边是磁带,从左到右速度越来越慢,容量越来越大,离CPU越来越远。在过去几十年的技术发展中,存储技术相对来说主要集中在最左边或者最右边,中间部分Nand是近20年才开始变得成熟。而Nand左侧的XP DIMMs/ReRAM等技术,则是过去几年才刚开始浮现的。想要把途中的各种Memory技术能梯度组合在一起,而且运用非常好,还是有一定难度。
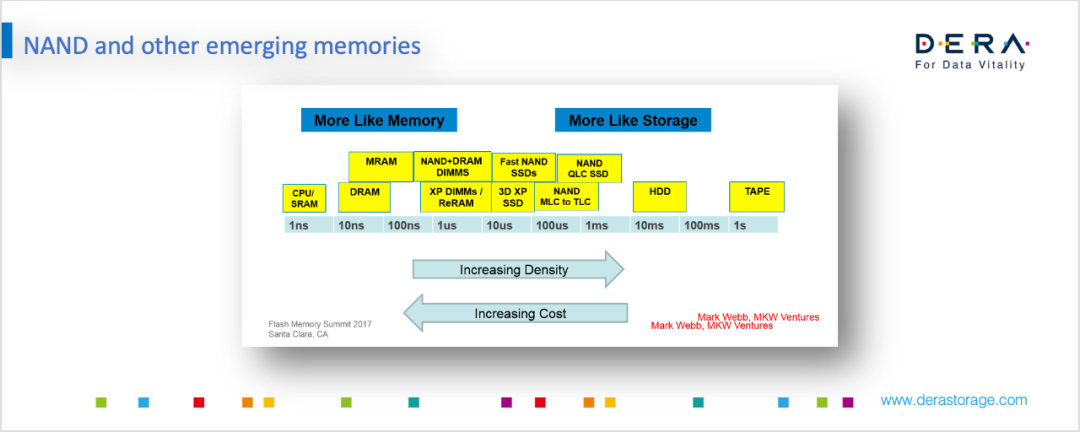
目前有很多公司在做类似的尝试,比如奥卡云就在用3DX Point做新的高性能存储。当然也有一些公司会采用偏保守的策略,需要Memory时,会简单粗暴的直接在PCIe上挂更多的DRAM,但我们相信,未来这种分层存储一定是发展的方向。
目前我们看到比较明确的趋势是MRAM可能会作为Cache放在SSD/ HDD/ Storage中,而且很多大厂已经开始把MRAM作为嵌入式存储,替代eflash放在芯片中。PCM、3DX Point和傲腾,应用于高性能SSD,或者作为Persistent Memory等。

Computational Storage
可计算存储近两年发展非常快,包括像SNIA工作组也成立了Computational Storage Work Group。可计算存储主要解决什么问题呢?首先,传统计算机结构里,需要把数据从Storage搬到Memory,然后被CPU处理之后再放回Storage,这样的数据搬移过程其实花费了大量总线带宽、运算资源能耗。随着大数据的普及,数据搬移的成本会越来越高,还可能带来一些安全性问题,这都需要我们去解决。
那为什么不把计算单元搬到数据端,这样一来就能解决上述提到的一些问题。所以现在有很多应用开始从计算为中心Compute-Centric迁移到Data-Centric。举两个场景比较适合的例子,比如说人脸识别,类似于这种模式识别或Pattern matching的运算,特别适合于把计算单元搬过来存储单元附近。假如说硬盘里有1万张人脸信息,用匹配的Pattern直接在硬盘里scan,匹配之后随即触发报警机制,然后上报,而不是把1万张人脸的数据信息搬到Memory再去做计算。
另外一个例子是人工神经网络和机器学习。人工神经网络本质上是一个通过非常多的小运算单元来做非线性拟和的算法,它有非常多神经元,而这也是为什么GPU更擅长于神经网络计算。GPU本质上有一个强调并行运算的处理架构,从新一代神经网络模型计算角度来讲,Data-Centric的架构更加适合于新的计算模式和新的科技发展。现在大量神经网络学习除了在使用GPU之外,也发展了一些更适合于神经网络计算的原生性架构。这些原生的用于神经网络计算的架构,就是让数据和神经元的权重计算靠近,省掉各种数据搬运的操作,这样的思路,可以想象在存储端的技术进步中也会应用过来。

目前跟SSD相关的可存储计算有一些简单的框架,如下图所示。左上角把一个computational processor直接放到SSD盘做可存储计算的卸载,比如说加密或者压缩算法等。左下角是一些公司在做的进一步尝试。如果说某项应用在今后被广泛应用,可以把它做成一个ASIC:把可存储计算和SSD Controller放在一起,这也是一种实现方式。
也可以考虑做一个可存储计算能力性能比较强的板卡,可覆盖多个SSD可存储运算的卸载需求,这样就是Host去连接这个可存储运算板卡,然后再挂一些SSD,这就是下图中间的一种模式。

另外,某些可存储运算并不是刚需,因此我们不把它放在Host和SSD主存储路径的关键路径上,而是比如挂在PCIe总线上,仅仅在需要时把数据送过来做卸载,不需要时,还是按照传统存储进行。
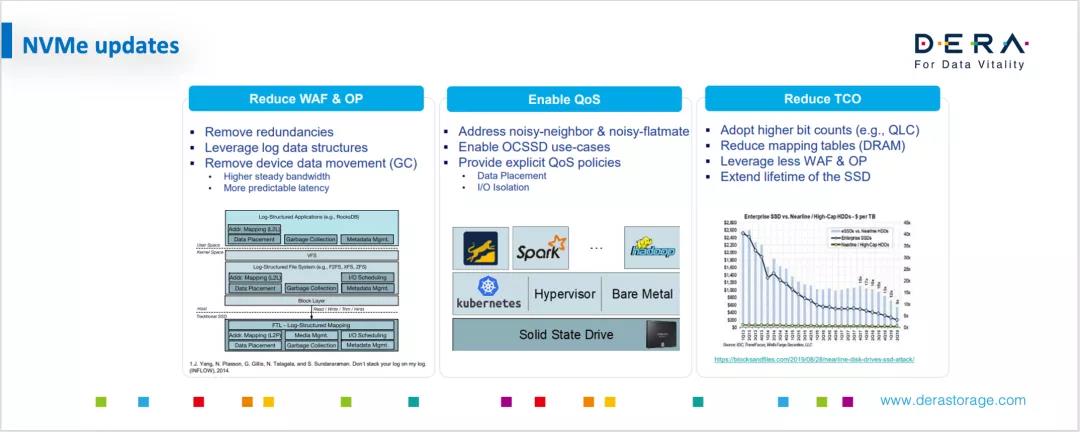
NVMe Updates
下面再谈一下关于NVMe标准的更新,以及一些新的发展趋势。首先,下图展示了近几年SSD根据NVMe标准快速演进的过程,从2016年1.2、2017年1.3、2019年1.4,然后2.0也即将推出。可以看出,这是一个不断丰富和完善的标准,同时也反映出这个行业的变化非常迅速。
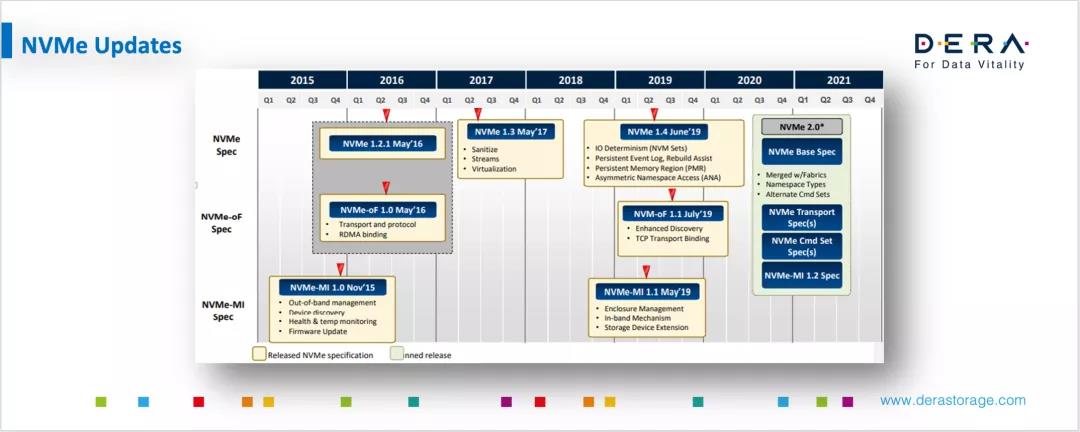
NVMe标准从一开始就是个非常简明优雅高效的标准。经过近些年的发展,NVMe标准也陆续推出很多版本,加进很多新特性,希望能够覆盖到越来越多的应用场景。这时NVMe组织依然想保持他们标准的简洁优雅高效,所以在推出2.0时会做一些refractor。
首先,NVMe定义了一个基本的Spec,然后制定标准定义可扩展模块,这样一来,用户在实际部署和开发产品的时候,可以根据自己的需要去选择使用哪些标准。再者,就是一些可选的命令集,比如KV的Command Set还是ZNS Command Set等。第三,是关于传输架构。最初的NVMe是基于PCIe架构,但在发展过程中,我们越来越意识到其实需要把存储做池化,把远端的存储拉到近端,这样就有了NVMe Over Fabric。刚开始可能都在运用一些传统的,例如像RDMA这种技术,但这需要重新改造现有网络。为什么不再推出一个能够跑在以太网上面的传输协议?因此后来就有了NVMe Over TCP/IP。最后是管理接口。这样来看,整个NVMe标准基于Base Spec,延伸出一些可以模块化的标准,供大家自由选择。

NVMe标准的更新中ZNS受到很多人的关注。ZNS可以理解为是对Open Channel概念的吸收。Open Channel的目的是把SSD和flash颗粒的能力呈现到Host,让Host能够更加高效的利用底层存储介质,从而提高产品的效率。
NVMe新标准也会做一些分区管理,用来降低各个区不同区块之间的噪音影响,提升QoS,而且会降低整个TCO。
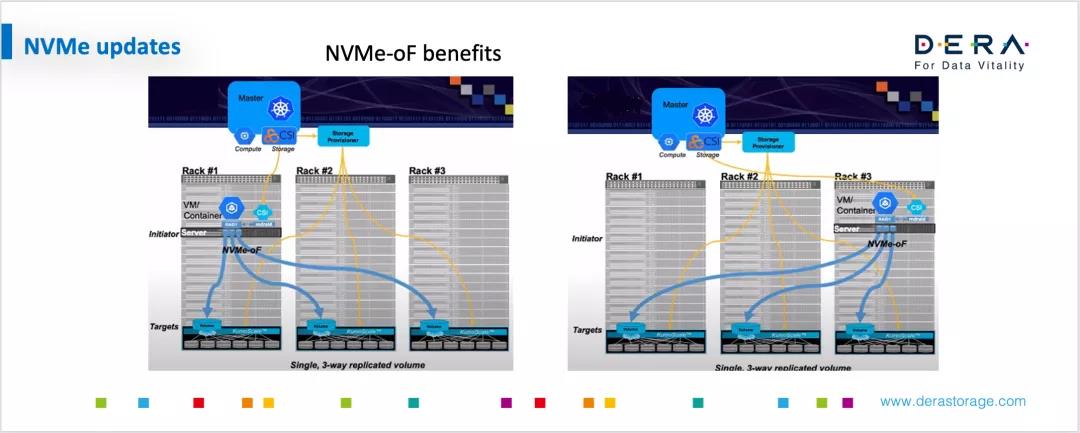
NVMe Over Fabric技术可以非常好的解决远端存储的延迟问题,可以最大可能的解决存储池化的问题。通过这些技术,可以实现比较高性能的存储池资源分享,而且数据的进入和移动都变得比较方便。下图可以在某种程度上来展示这种情况。
首先从下图可以看到,通过NVMe Over Fabric,Host可以比较灵活的迁移(假如说从一个机房里的rack到另外一个rack),并不需要做物理的改动,提升了整个机房的管理灵活性,给运维工作带来极大的好处。