1月26日,天数智芯发布三年架构路线图,聚焦打造“高质量算力”,以通用芯片为底座,提供高效率、可预期、可持续的AI++算力系统,以多项独创技术赋能应用场景。
迈向高质量算力
(天数智芯AI与加速计算技术负责人 单天逸)
大家好,我是天逸。很荣幸给大家做迈向高质量算力的报告,算力是数字经济的核心生产力,已经被运用在千行百业。但“规模堆砌式” 的传统路径,正让行业面临能效比偏低、创造力不足,实际使用困难等问题;而本次合作伙伴的目标,正是与各位共同探讨“如何将算力从‘量的扩张’转向‘质的跃升’”,报告里会公布天数在这一领域的实践成果,并且介绍现在和未来的架构路线图。

让我们回望20世纪,我们用测量与连接去探索已有的世界,去探索大自然的奥秘。我们在这期间取得了非凡的成就,我们有了电子显微镜,有了 GPS,有了手机,有了电视,我们能够看得更细,看得更远,连得更广,连得更准。但这一切,都还停留在对已有世界的测量与连接。
21 世纪,我们不再受限于对已有世界的探索。我们可以通过计算去创造新的事物,所以我们有了 Earth2,有了 AlphaFold, 有了 GPT, 有了 Deepseek,这些AI工具创造以前自然界从未拥有的东西,他们正在帮助我们创造一个全新的世界。
从“发现已知” 到 “创造未知”,算力,正是这场变革的核心引擎。

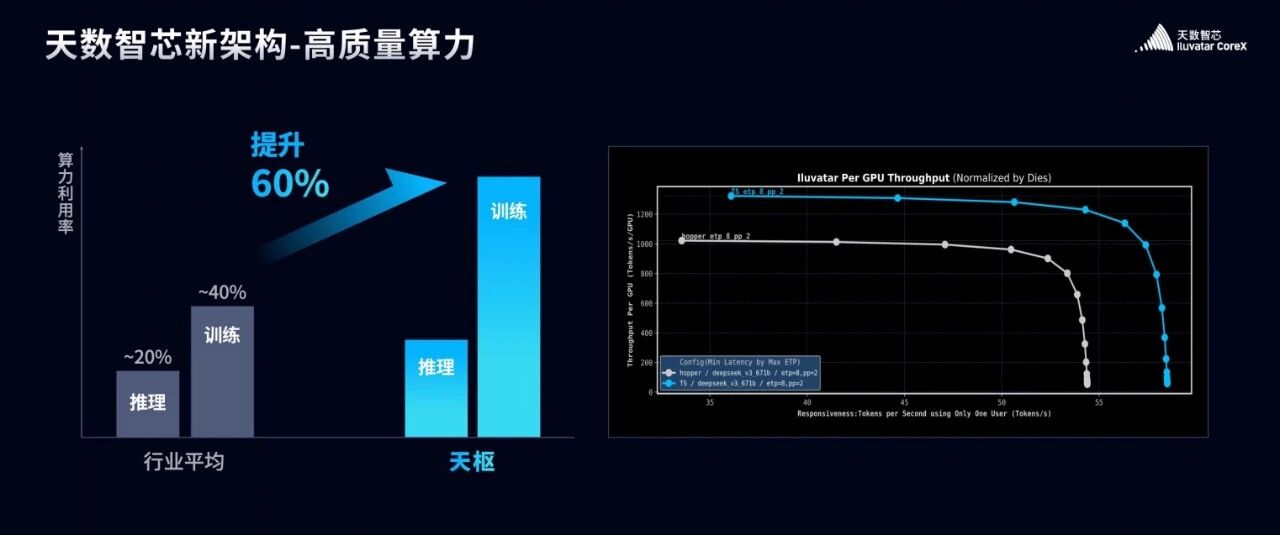
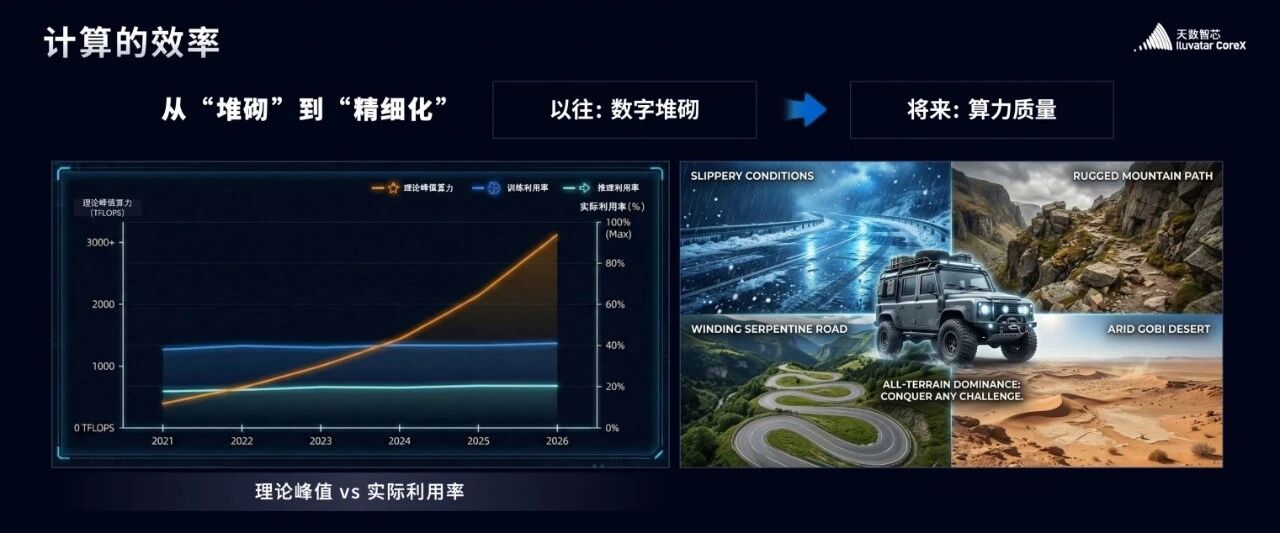
过去十年是算力野蛮增长的十年,规模的快速扩张确实带来了阶段性的产业繁荣。但繁荣背后,是难以忽视的效率困局。推理场景的平均利用率不足 20%,训练场景的平均利用率也仅在40%出头,我们的理论算力一路飙升,可到了实际应用场景里,效率却大打折扣。这种粗放式发展,直接导致了能效比失衡、算力资源严重浪费的问题。
那什么导致的这些问题?就像我们开车行驶,会发现我们可能面对各种各样的复杂情况,比如雨雪冰雹天气,崎岖的土路,蜿蜒的山路,荒芜广袤的戈壁;而我们所处的物理、芯片、系统世界也面临同样的挑战,计算,通讯,存储都会给我们带来各种障碍。所以幻想奔跑在平坦的赛道上毫无意义,我们要做的是越野车,面对种种不利的场景也能披荆斩棘,一往无前。
下面,我们来聊聊更核心的命题——芯片与创造。
我们不妨做个类比:
我们来用“应试教育”举例子,专用芯片,诞生目标非常明确,就是为了加速特定算法、特定指令,比如矩阵乘法、Softmax 这些主流任务,在限定的“题库” 里,它可以完成。
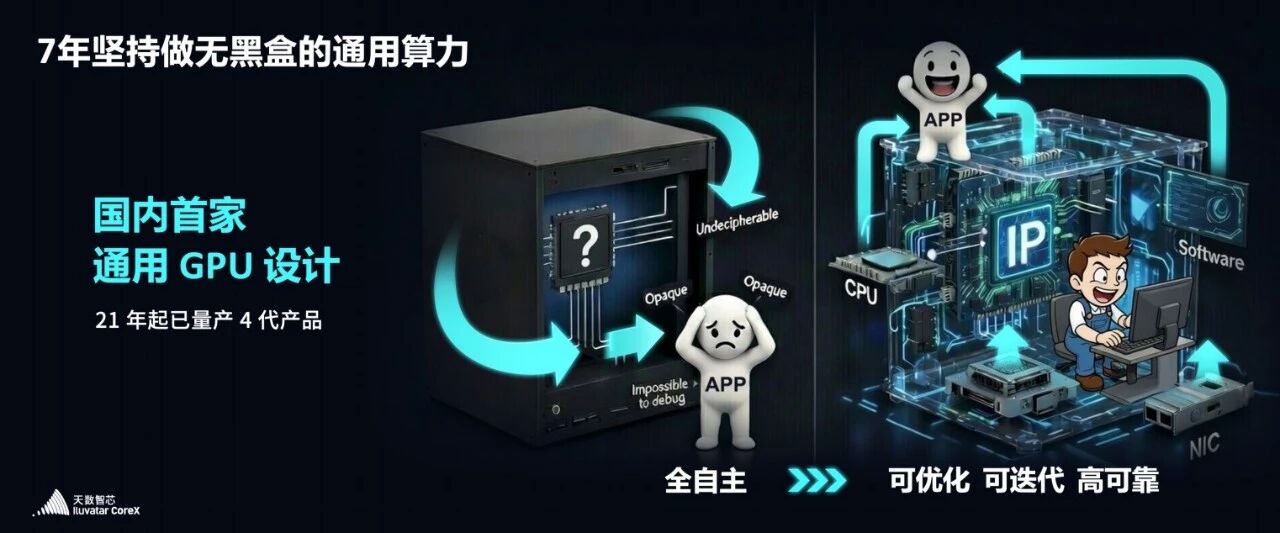
但天数所代表的通用芯片不一样。通用芯片的设计哲学,就是为了回归计算本质,支持所有种类的计算。 它既能高效支持的当前热点任务,也能从容支持那些我们还没想象到的全新算子、全新架构。
所以我们一直坚信:不要让算力的僵化,限制算法的进化。
硬件,绝不应该成为束缚算法探索的枷锁,而要做孵化新算法的坚实底座。
大家不妨回想一下人类的飞行史:
当我们执着于模仿鸟类拍打翅膀时,我们始终飞不上天;直到我们放下机械模仿,建起风洞去研究空气动力学,去探索飞行的本质规律,人类才真正学会了飞行。
今天,天数智芯的芯片,就想成为新世纪的“算力风洞”。帮助每一位研究者,去探索智慧的本质和边界。

大家可能要问天数的芯片,到底凭什么能支持未来的算法?
答案很简单:我们不设限。
接下来,我们回归计算的本质——
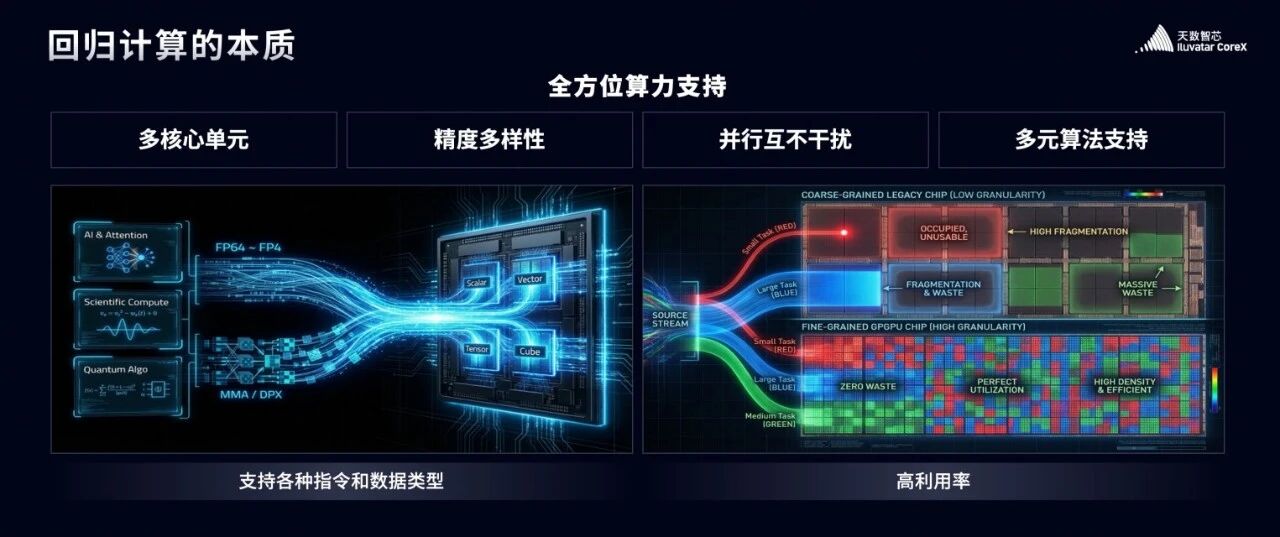
我们的芯片支持的不是某一类、某一种计算,而是几乎所有的数学运算图谱。从 Scalar、Vector、Tensor 到 Cube,从 FP64 到 FP4,从 MMA 到 DPX,不管是 AI 的 Attention 机制、前沿的科学计算,还是未来的量子计算相关模拟,我们全都支持。
再来看右边这张图——这是天数芯片的计算执行图。
大家可以看到,大任务、中任务、小任务,会被精准分配到不同的计算单元里。这就像一个规划科学的城市交通网,不会因为一辆重型卡车的通行,就堵死了所有的路。
而这背后,还有一个核心优势——超高密度的多任务核心。
这种多核心架构,让我们能实现更细粒度的任务拆解与分配,告别算力浪费,拉高计算效率。
我们把未来的高质量算力定义为:
第一,高效率: 能为客户创造最优的 TCO,实实在在帮客户节省使用成本。这就像一辆性能强悍的越野车,既能在平坦大道上疾驰,更能翻山越岭、闯过泥泞崎岖的路。
第二,可预期:我们可以通过精准的仿真模拟,让客户在拿到芯片、部署算力之前,就能清晰预判最终的性能表现,做到所见即所得。
第三,可持续:从现在主流的 CNN、RNN,到当下火热的 Transformer,再到未来还未诞生的全新算法,我们的算力始终能无缝适配。今天能用,明天更能用。

让我们把目光聚焦到天数芯片的高效率。
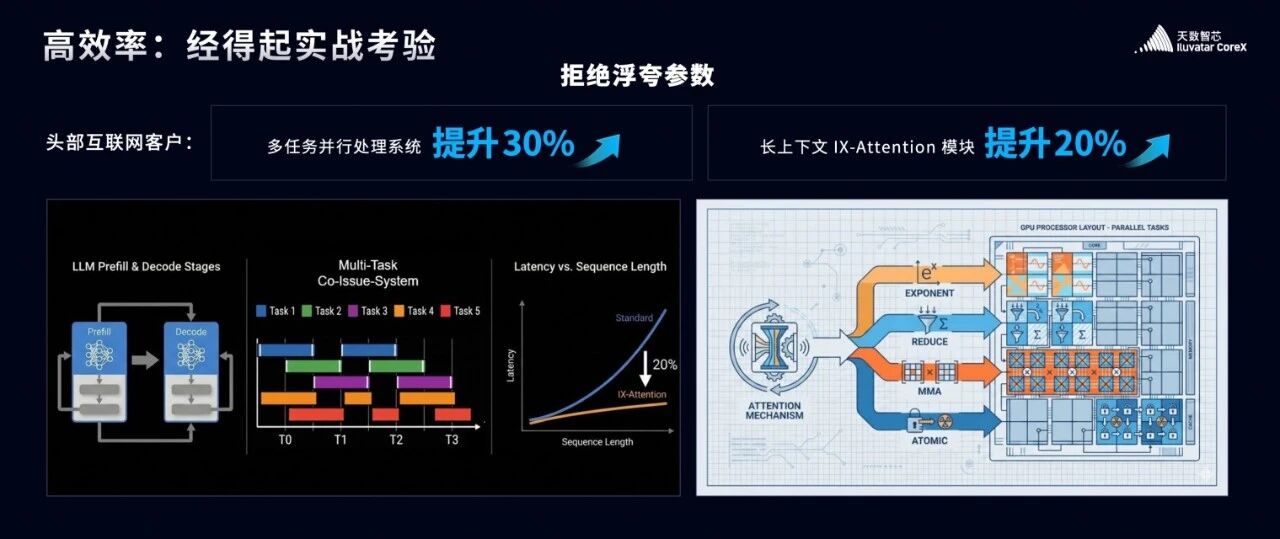
在当前PD 分离的架构下,我们的芯片不只是单纯做计算—— 还要扛下通信、KV 数据传输这些关键任务。
这些任务要是串行处理,效率会大打折扣;可要是直接并行跑,又很容易出现“任务撞车”,导致算力拥堵。
针对这个痛点,我们专门打造了IX并行任务处理模块。
它就像一位经验老道的交通交警,能精准调度 KV 传输、多路多流、计算与通信等各类任务,让它们并行不冲突。
最终,这个模块直接帮客户实现了端到端 30% 的性能跃升!
不止于此,我们还有IX Attention 模块。
Attention底层涉及exponent,reduce,MMA,Atomic等组件,我们的IX-Attention模块把这些部分有机地拼装到一起,
这个模块像一个乐队的指挥一样,让他们和谐地一起工作,最终实现了20%的性能提升,让大模型推理的“长上下文”不再可怕。
我们来看下我们的老朋友阶跃星辰。
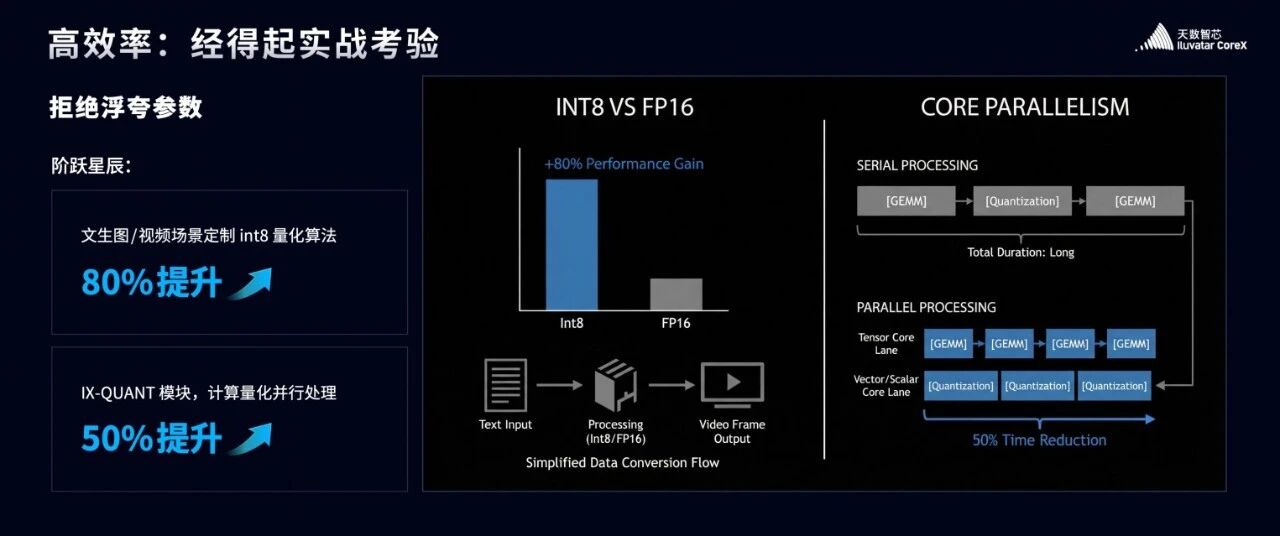
他们在文生视频、文生图等领域的实力有目共睹。在合作中,我们没有止步于“能跑”,而是深入底层,联合研发定制化的量化算法。
我们尝试了 Smoothquant、GPTQ、分组量化等多种方案,针对模型的不同层、不同精度,动态选择最精准的量化方式。最终,我们在完全不损失模型效果的前提下,硬生生把性能提升了80%!
同时,反量化带来的开销我相信也让很多软件优化工程师头疼,即使在国际主流GPU也是不可回避的难题,
天数的IX-QUANT模块实现了几乎无损的反量化,再原有基础上又提升了50%的性能,
正是这“组合拳”,让我们在实际业务中,性能全面超越了国际主流产品。
说完了效率,我们再说第二个核心——可预期。
我给大家举个生活里的例子:你想装修一套房子,预算 20 万、工期 3 个月。要是没做 3D 预览、没画设计图就直接动工,最后大概率会出问题 —— 瓷砖和沙发风格不搭,原本 20 万的预算花到了 30 万。
装修房子尚且如此,建设算力中心、搭建算力集群这种大工程,要是没有可预期性,后果可想而知。
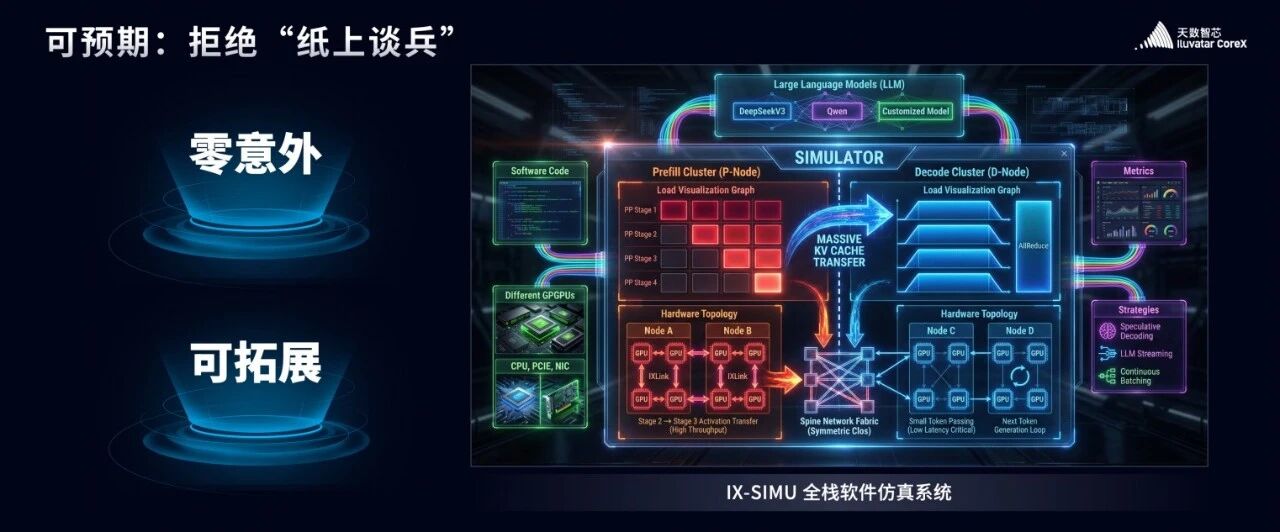
而我们这套仿真系统的目标,就是零意外、可预期。
你只需要把左上角的软件代码输入进来,系统会自动整合算力生产者(GPU)、CPU、网卡、PCIE 等硬件组件,匹配网络拓扑,再结合软件策略、投机策略、Streaming LLM 策略、前缀匹配等各类策略,最终精准输出 Deepseek、千问等任意模型的性能表现。
所以我们的产品会实现
“零意外”: “预判性能”,避免“意外的惊喜”;
“可预期”:从单卡到万卡集群的 “精密扩展”。
说完了可预期,我们来谈第三个核心要素——可持续。
为什么要强调可持续?因为现在的算法演进太快了,我们经常会遇到所谓的“计算墙”“传输墙”“存储墙”。只有具备可扩展性,才能最大程度这些墙带来的系统瓶颈,满足未来未知的计算需求。
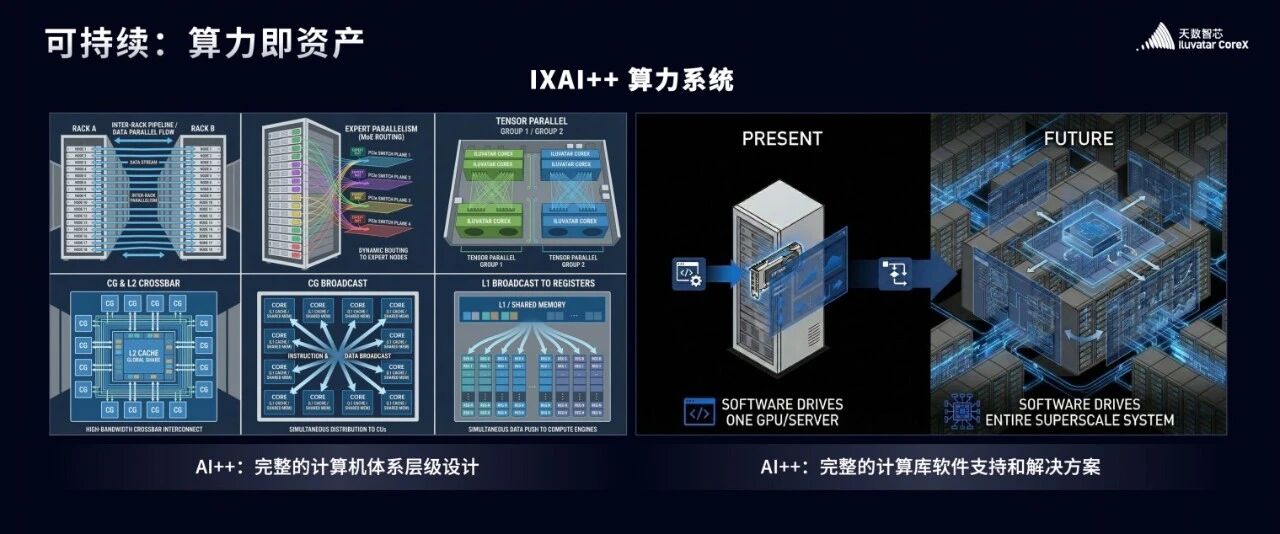
我们统一了芯片内与芯片外,来构建我们的算力系统。
所以我们不提scaling up和scaling out,让我们从体系结构的微观视角,来看看我们的系统是如何构建的:
大家都知道,数据的流动是系统设计的核心,我们把系统的数据流动定义为六层。
1.在核心内部:不同的寄存器将数据发给共享内存(Share Memory);
2.不同的核心组成CG,Share Memory把数据汇总给CG。
3.在芯片内部:不同的共享内存汇总给计算集群(CG),不同的 CG 再汇总给整个芯片(Chip);
4.在节点内部:不同的芯片将数据汇总给交换机(Switch);
5.在机柜内部:不同的节点交换机汇总给机柜交换机;
6.在集群之间:不同的机柜互联互通,最终完成巨量的计算任务。
这个系统,就像一支整齐划一的交响乐队为产生智慧而协同共鸣。
硬件是基石,我们将会提供怎样的软件来驱动这个庞大的系统呢?大家都知道:
从上世纪七十年代开始,软件经历了从驱动单片机,到个人 PC,到单机服务器,再到小型集群。
这一个又一个范式的转变,不仅见证了社会的变迁,更是生产力爆发的源泉。
在未来,我们要从软件驱动芯片/单机变为软件驱动整个系统。
建立“软件驱动算力系统” 的全新范式!
用软件的“智慧”,去释放硬件的“潜能”!
我们的可持续同时体现在不断更新的软件栈和软件系统
三类库共同支持和保障多场景的高效运行
底层库是基石:
AI 库:承接 AI 任务的算法与加速需求;
通讯库(ixccl):解决多机多卡的协同问题,支撑大规模算力集群的互联;
加速计算库:提供传统科学计算的基础算法模板。
模型与计算中间层是支柱:
在基石之上,我们直接支撑各类神经网络模型CNN,Transformer,LSTM与高性能计算的各个领域
上层是繁荣的应用生态:
基于稳固的基石与支柱,我们开拓出广阔的应用空间。
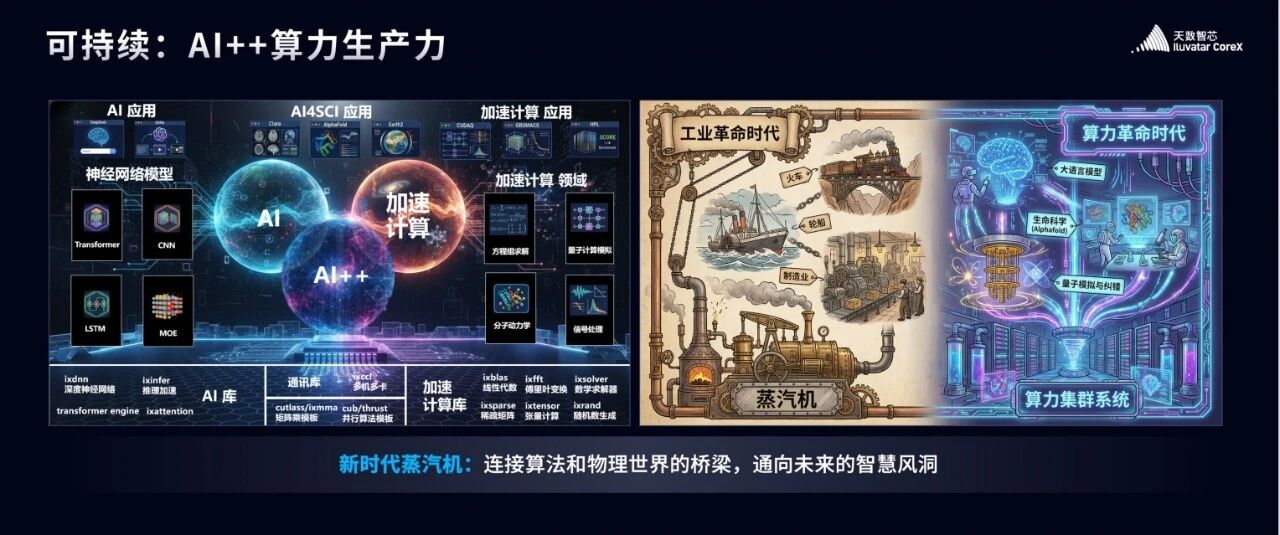
我们提供各类AI应用DeepSeek,SORA等。
我们同样支持AI4Sci的相关应用包括蛋白质结构预测(AlphaFold)、医疗影像分析(Clara)、气候模拟(Earth2)等
我们还会提供量子计算的平台cudaQ,分子动力学Gromacs,大规模方程组求解器HPL等。
我们把我们的整个系统称之为“AI++算力系统”,大家都知道C和C++,意思是自我迭代,不止于AI。
200 多年前,瓦特改良了蒸汽机。
从此蒸汽机成为连接能源和物理的桥梁,以这台机器为动力源头,火车穿梭大地、轮船远航深海,第一次工业革命就此爆发,彻底颠覆了人类的生产与生活方式。
而今天,天数智芯所构建的算力系统,正成为一座全新的桥梁—— 一座连接算法创新与物理世界的桥梁。
我们的算力,能支撑 AlphaFold 破解生命的未解之谜,探索基因密码的终极答案;我们的算力,能模拟并纠错量子计算,为下一次计算范式的变革,铺平前行的道路。
200 多年前,谁掌握了蒸汽机,谁就握住了开启工业革命的钥匙;
200 多年后,谁拥有了顶尖的算力系统,谁就有资格引领新一轮产业革命的浪潮。
因为我们坚信:算力系统,就是我们新时代通往未来的“风洞”,承载着人类科技向未知探索的无限可能。
但我们仰望星空,发现北斗七星在帮我们指引着前行的方向,我们也相信我们的算力系统也能为高质量算力的发展指引方向。
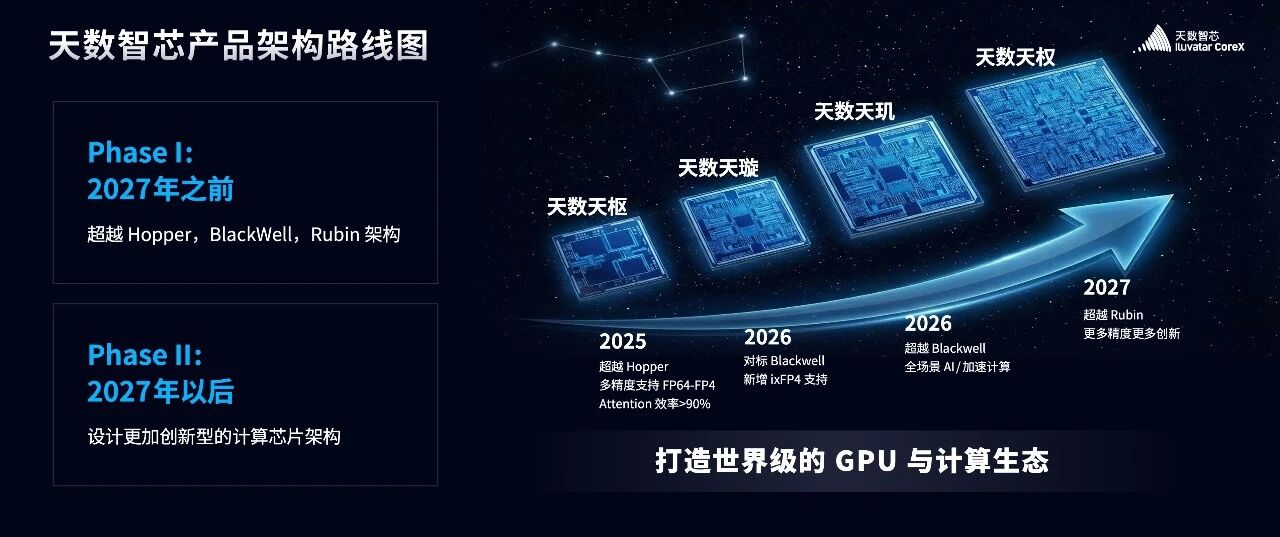
千呼万唤使出来,下面我们就公布一下公司现在和未来的架构路线图
分为时间节点布局与阶段目标两部分:
按年份推进的产品迭代,逐步实现对行业主流架构的对标与超越:
2025 年,天数天枢架构:对标Hopper 架构,支持 FP64-FP4 多精度;超越 Hopper Attention 效率超 90%;
2026 年,天数天璇架构:部分对标 Blackwell 架构,新增 ixFP4 精度支持;
2026 年,天数天玑架构:全面超越 Blackwell,覆盖全场景 AI / 加速计算;
2027 年,天数天权架构:全面超越 Rubin 架构,支持更多精度与创新设计。
我们的阶段发展目标
Phase I(2027 年之前) :核心是超越行业标杆架构(Hopper、Blackwell、Rubin),通过多代产品完成对目前国际顶尖水平的追赶;
Phase II(2027 年之后) :更加转向创新架构设计,用更具突破性的技术实现计算芯片架构设计。
我们相信那些看似遥不可及的梦想,在未来都会实现
优秀的架构设计,代表着优秀的PPA,下面我就向大家介绍下天数芯片的创新架构设计。
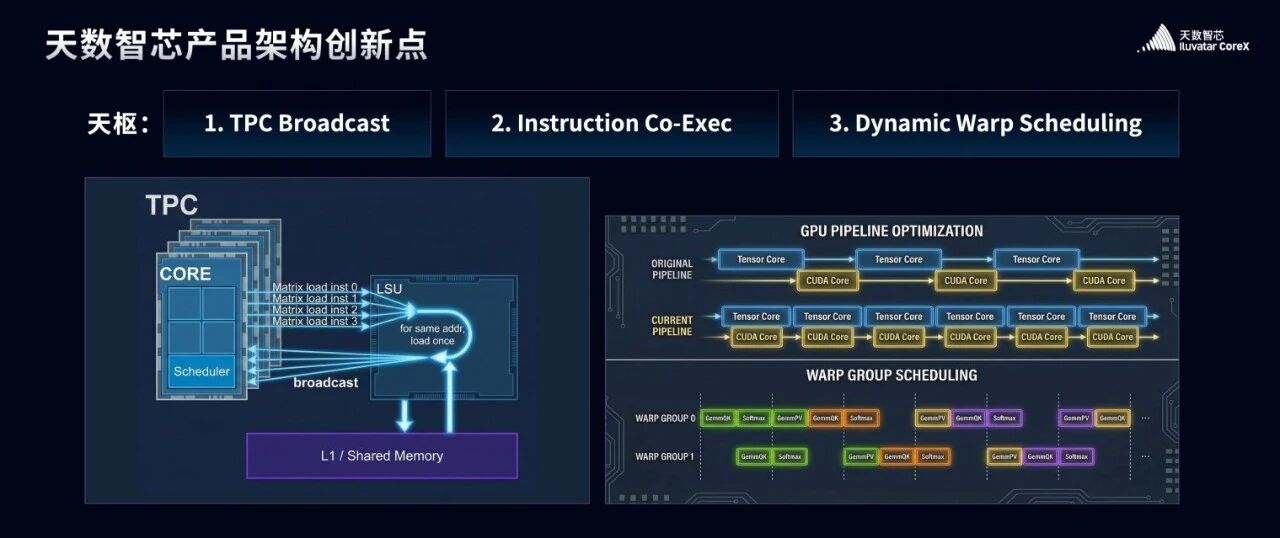
技术创新:TPC BroadCast 设计
创新架构:在系统设计中,单纯增加带宽的开销很大,就像在城市的马路中单纯拓宽马路来承载更多车流一样,会有很大的面积开销。所以我们并没有单纯的放大带宽,而是追求单位带宽下实现更好的效果。当我们发现有相同地址的数据时候,芯片内部的load store单元不会进行重复无用的访问,而是在上游进行BroadCast,大大减少了访存功耗,等效提升访存带宽,用相同的访存带宽实现了最好的效果,就像在城市里,用相同的马路宽度承载了更高的车流量。
技术创新:Instruction Co-Exec 设计
我们的指令处理系统可以同时运行不同指令,不单单是Tensor core和Vector core,我们同时加入了Exponent,通讯,三角函数等操作,在天数的IX-Scheduler模块中,用最小的cost增强了不同指令并行处理的能力,别担心MLA,也别担心Engram,更别担心DeepSeekV4,我们会并行的为你处理这些。
技术创新:Dynamic Warp Scheduling 设计
创新架构:在我们的微架构中,可以驻留更多的warp,这些warp有的时候不会完全听话,会为了一个资源打打闹闹,天数首创了Dynamic Warp Scheduling机制,动态的scheduling让这些warp学会谦让,大家会有序的等待,不会让计算资源闲着,也不会争抢同一个计算资源,而是更有序的在芯片的世界中工作,为我们源源不断地提供智慧。
那我们再把目光投向架构DeepSeek。
在 DeepSeek V3 的论文中,他们非常专业且详细地阐述了软硬件生态的发展趋势,同时也 “吐槽” 了两个让他们非常头疼的痛点。
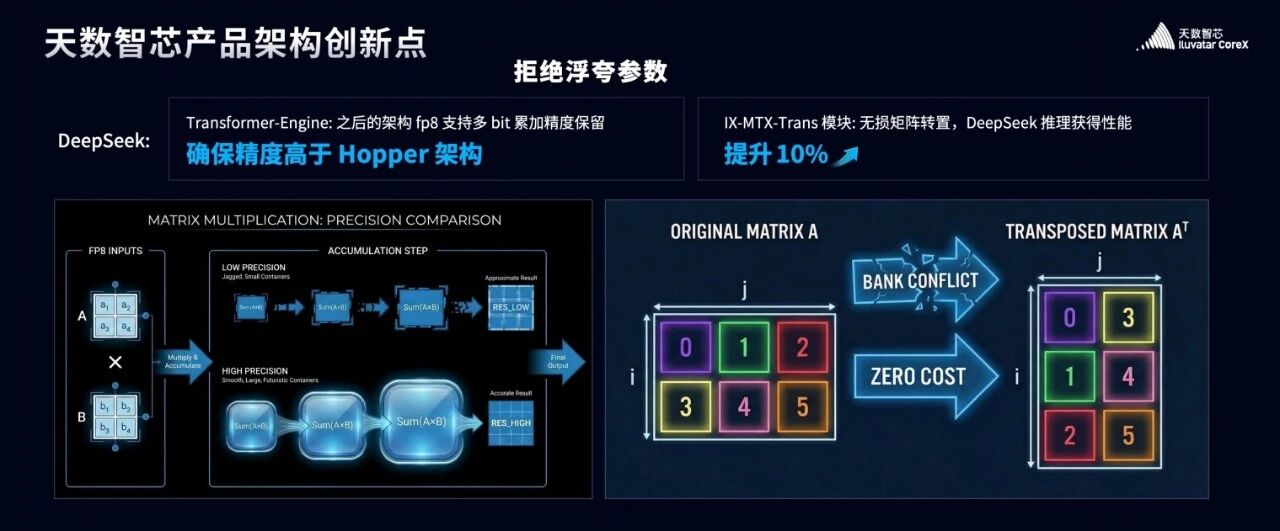
第一个痛点是 FP8 的累加精度。
论文中提到,累加精度不够给研发同事带来了很多困惑和问题。
但在天数芯片的 Transformer-Engine 架构中,这个问题不复存在。 我们支持用户任意保留累加位数,实现了精度更高、更准的 FP8 计算,完美解决了这个精度焦虑。
第二个痛点是矩阵转置带来的开销。
我相信这也是很多软件优化工程师的噩梦,DeepSeek 的同事们也在论文中专门提及了这一点。
为此,我们在 Transformer-Engine 中特意加入了 IX-MTX-Trans 模块。 它能保证无损的矩阵转置,没有bank conflict,没有冲突,不仅在训练场景下节省了大量显存,更在 DeepSeek V3 的推理场景中,直接带来了10% 左右的性能提升。
我们的天枢架构的效率会比现在我们看到的最优秀的架构高60%左右的效率。
最后给大家留下了一个彩蛋,就是我们天数天枢架构的芯片和Hopper架构在DeepSeekV3场景的表现对比图,已经实现对Hopper20%的性能超越。谢谢大家。