

• Vision Mamba 论文链接:
https://arxiv.org/abs/2401.09417
• 项目主页:
简介
本文的工作Vision Mamba[1]发表在ICML 2024。研究的问题是如何设计新型神经网络来实现高效的视觉表示学习。该任务要求神经网络模型能够在处理高分辨率图像时既保持高性能,又具备计算和内存的高效性。先前的方法主要依赖自注意力机制来进行视觉表示学习,但这种方法在处理长序列时速度和内存使用上存在挑战。论文提出了一种新的通用视觉主干模型Vision Mamba,简称Vim1,该模型使用双向状态空间模型(SSM)对图像序列进行位置嵌入,并利用双向SSM压缩视觉表示。在ImageNet[2]分类、COCO[2]目标检测和ADE20k[3]语义分割任务中,Vim相比现有的视觉Transformer[4](如DeiT[5])在性能上有显著提升,同时在计算和内存效率上也有显著改进。例如,在进行分辨率为1248×1248的批量推理时,Vim比DeiT快2.8倍,GPU内存节省86.8%。这些结果表明,Vim能够克服在高分辨率图像理解中执行Transformer样式的计算和内存限制,具有成为下一代视觉基础模型主干的潜力。
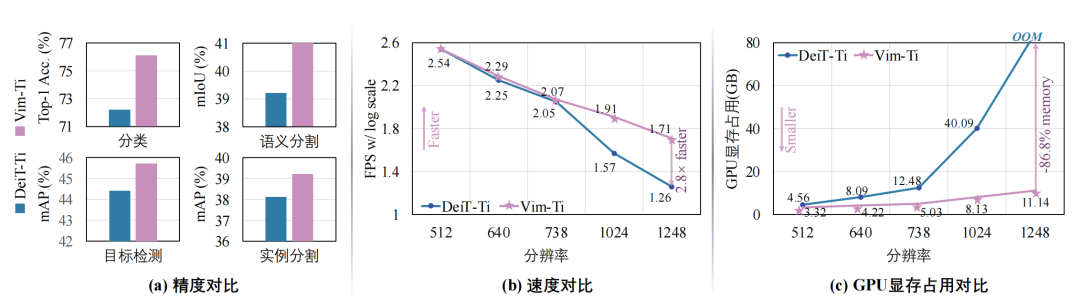
图1 本文所提出的Vision Mamba (Vim)和基于Transformer的DeiT模型进行精度与效率对比:Vim在图像分类、目标检测、语义分割、实例分割任务上获得了更好的精度,且在高清分辨率图像处理上呈现出巨大的优势。
研究背景
图像表示学习是计算机视觉领域的重要研究课题,其目的是通过模型学习从图像中提取有意义的特征,从而应用于各种视觉任务中。目前,视觉Transformer(Vision Transformer, ViT[4])和卷积神经网络(Convolutional Neural Networks, CNNs)是图像表示学习中最常用的方法。然而,这些方法在理论上存在一些局限性。
视觉Transformer利用自注意力机制能够取得全局的感受野,在大规模自监督预训练和下游任务中表现出色,但其自注意力机制在处理长序列依赖和高分辨率图像时,带来了计算和内存的巨大开销。具体而言,自注意力机制的计算复杂度是输入的图像块序列长度的平方,这使得其在处理高分辨率图像时非常耗时且占用大量内存。尽管一些研究提出了改进方法,如窗口注意力机制[6,7],但这些方法虽然降低了复杂度,但导致感受野被局限在局部的窗口内部,失去了原本全局感受野的优势。
另一方面,卷积神经网络在处理图像时,通过使用固定大小的卷积核来提取局部特征。然而,卷积神经网络在捕捉全局上下文信息方面存在局限性,因为卷积核的感受野是有限的,虽然一些研究引入了金字塔结构或大卷积核来增强全局信息提取能力,但这些改进仍然无法完全克服CNN在处理长序列依赖方面的不足。
在自然语言处理领域,Mamba[11]方法的出现给高效率长序列建模带来了很好的发展契机。Mamba是状态空间模型(state space model, SSM)方法的最新演进。Mamba提出了一种输入自适应的状态空间模型,能够更高质量地完成序列建模任务。与此同时,该方法在处理长序列建模问题时有着次二次方的复杂度与更高的处理效率。然而,Mamba方法并不能够直接应用于视觉表征学习,因为Mamba方法是为自然语言领域的因果建模而设计的,它缺少对于二维空间位置的感知能力以及缺少全局的建模能力。
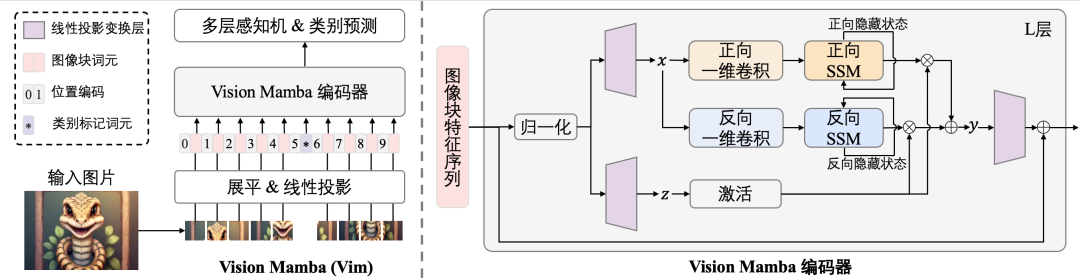
图2 本文所提出的Vim模型的网络构架图。
为了克服上述Transformer和CNN的理论局限性,启发于自然语言处理领域Mamba的成功,本文提出了一种新的通用视觉主干模型——Vision Mamba (Vim)。该模型基于状态空间模型[10](State Space Models, SSMs),利用其在长序列建模中的高效性,提供了一种新的视觉表示学习方法。该模型提出了双向状态空间模型来适配视觉特征的多方向性,并引入位置编码来针对图像单元进行标记。本文提出的Vim模型通过双向SSM对图像序列进行位置嵌入和压缩,不仅在ImageNet分类任务上表现出色,还在COCO目标检测和ADE20k语义分割任务中展示了优异的性能。与现有的视觉Transformer如DeiT相比,Vim在计算和内存效率上有显著提升。
Vision Mamba方法介绍
“状态空间模型
状态空间模型,比如结构化状态空间序列模型[10](S4)和Mamba[11]是启发于连续系统,该系统通过隐藏状态将一维函数或序列映射到。该系统使用作为演化参数,并使用和作为投影参数。连续系统的工作方式如下:
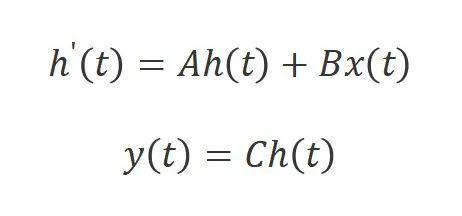
S4和Mamba是连续系统的离散版本,它们包含一个时间尺度参数,用于将连续参数A和B转换为离散参数和。常用的方式是零阶保持,其定义如下:
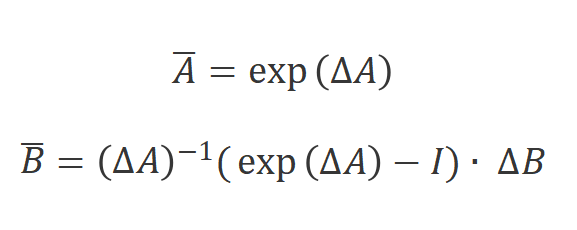
将和离散化后,使用步长的离散版本可以重写为:
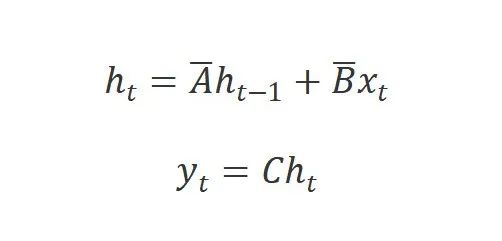
最后,模型可以使用全局的卷积来并行的计算:

其中是输入序列的长度,是结构化的卷积核。
“Vision Mamba结构
所提出的Vision Mamba如图1所示。标准的Mamba模块是为一维的文本序列所设计的。为了适配视觉信号,我们首先将二维图像转换为展平的二维图像块序列,其中是输入图像的尺寸,C是通道数,P是图像块的尺寸。接下来,我们将线性投影到大小为D的向量,并添加位置编码,如下所示:

其中是中的第个图像块,是可学习的投影变换矩阵。受ViT[4]的启发,我们也使用类别标记来表示整个图像块序列。然后,我们将标记序列输入到Vim编码器的第层,并得到输出。最后我们对输出类别标记进行归一化,并将其送入多层感知机(MLP)分类头以获得最终类别预测:
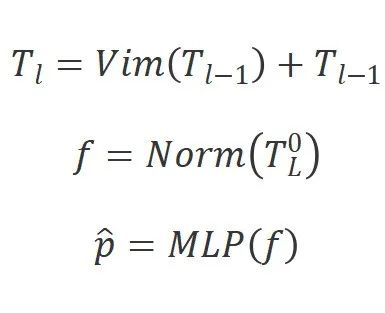
其中Vim是提出的视觉Mamba模块, 是层数,是归一化层。
算法1:Vim模块流程
输入:图像块序列 Tl-1
输出:图像块序列 Tl

“Vim模块
原始的Mamba模块是为一维序列设计的,不适用于需要空间感知理解的视觉任务。我们创新性提出Vision Mamba编码的基本构建模块Vim模块,如图2右侧所示。具体来说,像我们在算法1中所展示的操作。输入的标记序列首先通过归一化层进行归一化。接下来,我们将归一化后的序列线性投影到维度大小为的和。然后,我们从前向和后向两个方向处理。对于每个方向,我们首先对进行一维卷积,得到。然后,我们将线性投影到。然后用于分别离散化得到和。最后我们通过SSM计算前向输出和反向输出,并通过进行门控,并加在一起得到输出标记序列。
“效率优化
Vim通过借助于Mamba的硬件友好的实现方式确保运行的效率。优化的关键思想是避免GPU的I/O瓶颈和内存瓶颈。
IO高效性。高带宽存储器(HBM)和SRAM是GPU的两个重要组成部分。其中,SRAM具有更大的带宽,而HBM具有更大的存储容量。标准的Vim的SSM操作在HBM上需要的I/O数量是O(BMEN),其中B为批量大小,M为图像块序列长度,E 表示扩展状态维度,N 表示 SSM 维度。受到Mamba的启发,Vim首先将O(BME+EN)字节的内存从较慢的HBM读取到较快的SRAM中。然后Vim在SRAM中获取对应的参数,并执行SSM操作,最终将输出结果写回HBM。此方法可以讲I/O数量从O(BMEN)降低到O(BME+EN)从而大幅度提升效率。
内存高效性。为了避免内存不足问题并在处理长序列时降低内存使用,Vim选择了与 Mamba 相同的重计算方法。对于尺寸为 (B.M,E,N)的中间状态来计算梯度,Vim在网络的反向传递中重新计算它们。对于激活函数和卷积的中间激活值,Vim 也重新计算它们,以优化 GPU 的内存需求,因为激活值占用了大量内存,但重新计算速度很快。
计算高效性。Vim模块中的SSM算法和Transformer中的自注意力机制都在自适应地提供全局上下文方面起到了关键作用。给定一个视觉序列和默认的设置。全局注意力机制和SSM的计算复杂度分别为:
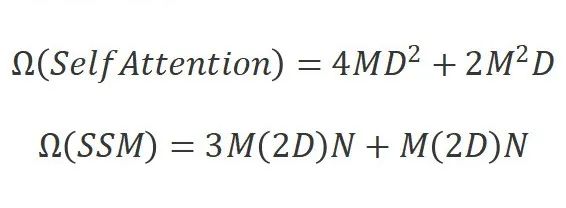
其中,自注意力机制的计算复杂度和序列长度成平方关系,而SSM的计算复杂度和序列长度呈线性关系。这种计算效率使得Vim在处理具有长序列长度的千兆像素级别应用时具有良好的扩展性。
实验结果
该方法在标准的大型图片分类数据集ImageNet-1K上进行验证。并将分类训练好的模型作为预加载权重用于下游图片密集型预测任务中去,如COCO数据集上的目标检测和实力分割任务, ADE20K上的像素级别的语义分割任务。
“分类对比
如表1与当前主流的分类模型对比Vim显示出了相当的精度,将Vim和基于CNN、Transformer和SSM的主干网络进行比较,Vim显示了相当甚至更优的性能。例如,在参数量相同的情况下Vim-Small的准确率80.3%,比ResNet50[12]高出了4.1个百分点。与传统的基于自注意力机制的ViT[4]相比,Vim在参数数量和准确率上均有显著提升。与视觉Transformer ViT高度优化的变种DeiT相比,Vim在不同模型尺度上均以相似的参数数量取得了更好的精度。
如图1所示,Vim的优越的效率足以支持更细粒度的微调,在通过细粒度微调后,与基于SSM的S4ND-ViT-B[13]相比,Vim在参数数量减小3倍的情况下达到了相似的精度,Vim-Ti+,Vim-S+和Vim-B+的结果均有所提高。其中,Vim-S+甚至达到了与DeiT-B相似的效果。
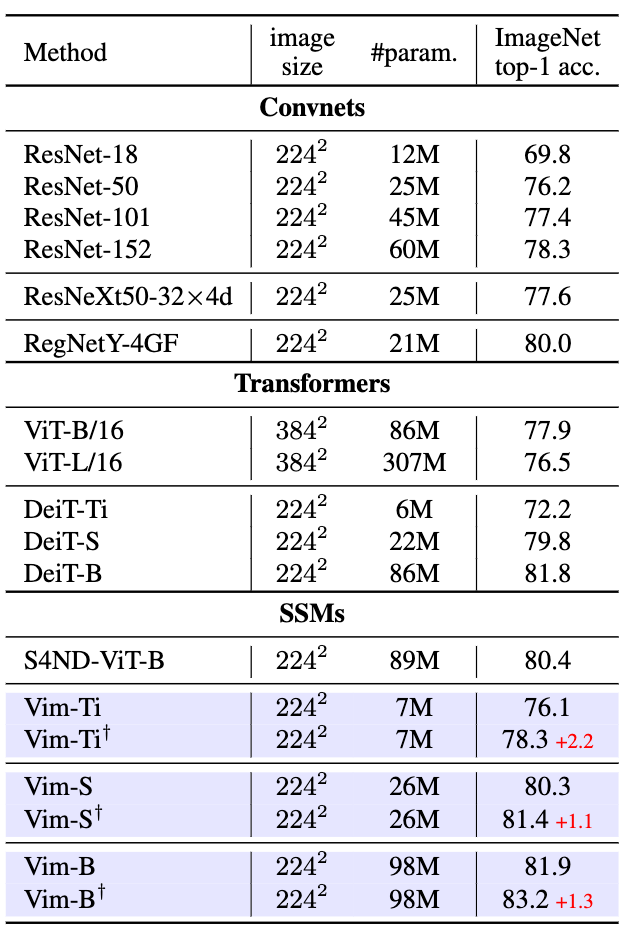
表1 ImageNet-1K分类骨干网络对比
“语义分割对比
在ADE20K语义分割数据集上,我们将ImageNet-1K上训练好的权重加载到UperNet[14]分割器中,使用Vim作为骨干网络进行特征提取,如表3所示,Vim取得了相比于CNN网络ResNet更少的参数量以及更高的精度,去Transformer模型DeiT相比,Vim取得了更优的精度。
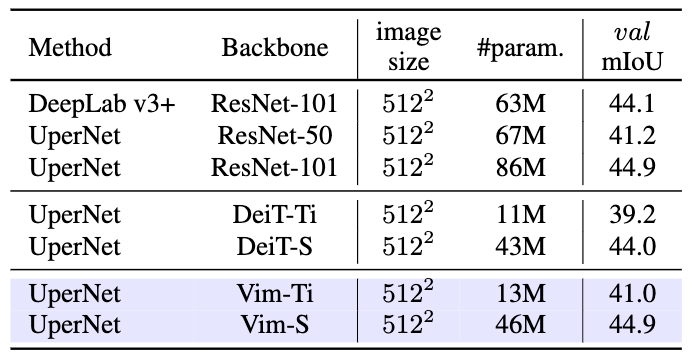
表2 ADE20k语义分割对比
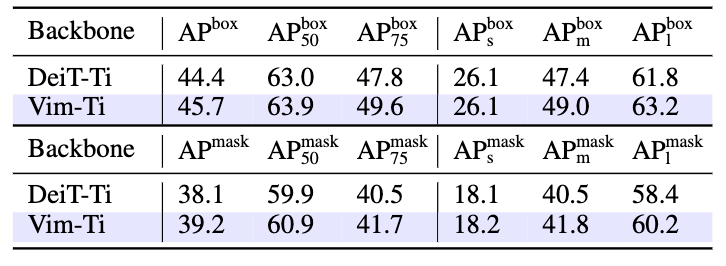
表3 COCO目标检测和实例分割对比
“目标检测与实例分割对比
在COCO目标检测与实例分割数据集上,我们将ImageNet-1K上训练好的权重加载到Cascade-RCNN框架中,使用Vim作为骨干网络进行特征提取,如表3所示,Vim取得相对于Transformer的DeiT更好的检测框精度和实例分割精度。值得注意的是,在高清图像输入的目标检测任务上,图像输入分辨率为1024×1024,由于Transformer的平方复杂度,需要将自注意力机制限制在固定大小的窗口内, 而Vim得意于其线性复杂度,无需窗口化,可以进行全局的视觉特征感知,从而取得了相对于表3中窗口化DeiT更好的精度。
“消融实验
双向SSM。如表4所示,双向SSM相较于原本的单向SSM取得了更高的分类精度, 且在下游的密集型预测任务上取得更为显著的优势。这一结果显示了本文提出的双向设计对于视觉特征学习的必要性与重要性。
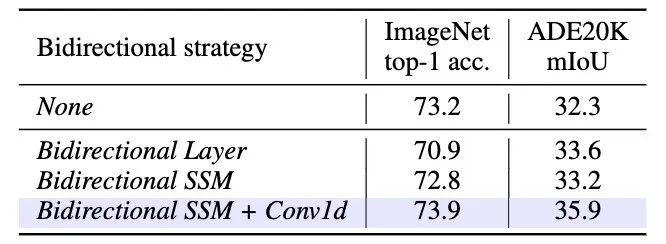
表4 双向SSM建模消融实验
分类策略。在表5中,我们探索了以下几种分类策略:

表5 分类策略消融实验
· Mean pool,将最后Vision Mamba编码器输出的特征进行平均池化。
· Max pool,将最后Vision Mamba编码器输出的特征进行最大化池化。
· Head class token,将类别标记词元置于图像块序列头部。
· Double class token,将类别标记词元置于图像块序列两端。
· Middle class token,将类别标记词元置于图像块序列中间。
如表5所示,实验结果表明,中间类别标记策略能够充分利用SSM的循环特性和ImageNet中的中心对象先验,展示了最佳的top-1准确率76.1。
总结
该论文提出了Vision Mamba (Vim),以探索最新的高效状态空间模型Mamba作为通用视觉主干网络。与以往用于视觉任务的状态空间模型采用混合架构或等效的全局二维卷积核不同,Vim以序列建模的方式学习视觉表示,并未引入图像特定的归纳偏置。得益于所提出的双向状态空间建模,Vim实现了数据依赖的全局视觉上下文,并具备与Transformer相同的建模能力,同时计算复杂度更低。受益于Mamba的硬件感知设计,Vim在处理高分辨率图像时的推理速度和内存使用显著优于ViTs。在标准计算机视觉基准上的实验结果验证了Vim的建模能力和高效性,表明Vim具有成为下一代视觉主干网络的巨大潜力。
参考文献:
[1] Zhu L, Liao B, Zhang Q, et al. Vision mamba: Efficient visual representation learning with bidirectional state space model. In ICML 2024.
[2] Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database. In CVPR 2009.[3] Lin T Y, Maire M, Belongie S, et al. Microsoft coco: Common objects in context. In ECCV 2014.
[4] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR 2021.
[5] Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention. In ICML 2021.
[6] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV 2021.
[7] Li Y, Mao H, Girshick R, et al. Exploring plain vision transformer backbones for object detection. In ECCV 2022.
[8] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. In NeurIPS 2017.
[9] LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. In Proceedings of the IEEE 1998.
[10] Gu A, Goel K, Ré C. Efficiently modeling long sequences with structured state spaces. In ICLR 2022.
[11] Gu A, Dao T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023.
[12] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In CVPR 2016.
[13] Nguyen E, Goel K, Gu A, et al. S4nd: Modeling images and videos as multidimensional signals with state spaces. In NeurIPS 2022.
[14] Xiao T, Liu Y, Zhou B, et al. Unified perceptual parsing for scene understanding. In ECCV 2018.
[15] Cai Z, Vasconcelos N. Cascade r-cnn: Delving into high quality object detection. In CVPR 2018.
[16] Liao B, Wang X, Zhu L, et al. ViG: Linear-complexity Visual Sequence Learning with Gated Linear Attention. arXiv preprint arXiv:2405.18425, 2024.
[17] Zhu L, Huang Z, Liao B, et al. DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention. arXiv preprint arXiv:2405.18428, 2024.
[18] Peebles W, Xie S. Scalable diffusion models with transformers. In CVPR 2023.







