
生成式AI引领智能革命成为产业升级的核心动力并点燃了“百模大战”。多样化的大模型应用激增对高性能AI芯片的需求,促使行业在摩尔定律放缓的背景下,加速推进2.5D、3D及3.5D异构集成技术。与此同时,AI的驱动作用正在助力EDA和半导体产业实现颠覆性的变革。
在现今AI时代,AI芯片设计将面临哪些挑战?EDA与IP工具又将如何借助AI的力量来应对这些挑战?12月11-12日上海集成电路2024年度产业发展论坛暨第三十届中国集成电路设计业展览会(ICCAD - Expo 2024)上,楷登电子(Cadence)数字设计及签核事业部产品验证群总监李玉童,以及楷登电子技术支持总监李志勇分别带来了题为《3D-IC – 打破AI芯片的设计桎梏》以及《基于标准的协议对未来人工智能工作负载至关重要》的精彩演讲,深入探讨了这些问题。
3D-IC – 打破AI芯片的设计桎梏
生成式AI推动了大模型应用的蓬勃发展,这一浪潮已蔓延至EDA领域。在这一趋势的引领下,Cadence推出了其全面的“芯片到系统”AI驱动的EDA工具平台—Cadence JedAI Platform,这一平台正是AI大模型浪潮下应运而生的创新工具。通过JedAI这个统一的数据平台,可以有效地进行数据存储、分类、压缩和管理,推动 EDA 工具和设计流程的自我学习优化,从而实现生产力的极大提升以及功耗、性能和面积(PPA)的进一步优化。
李玉童在演讲中介绍,JedAI平台采用分层的大型语言模型(LLM)训练架构,包含四个层级。最底层是开源基础模型,由第三方利用公共数据进行训练。在此基础上,Cadence利用专有数据训练出专属模型,以更好地满足芯片设计客户的需求。客户可以在Cadence模型的基础上,使用自身的数据进行进一步训练,从而生成私有模型。最顶层是用户界面,允许用户通过自然语言输入各种请求,与Cadence JedAI大型语言模型进行交互,以获得所需的专业解答。诸如此类的大模型应用中,AI芯片成为支撑引擎,为大模型应用提供强有力的支持。而大模型应用的繁盛,让AI芯片的发展来到了一个新高度。
不难看出,LLM的参数量指数级增长对与处理器匹配的内存系统提出了更高的要求,AI存储要求更大容量、更大带宽、更低功耗,从而使得AI芯片的设计面临前所未有的挑战。
HBM是此前克服“内存墙”(Memory Walls)的主要解决方案,其强大的I/O并行化能力,使HBM成为Al系统中用于训练和推理的高规格存储设备,且已经成为大部分高端数据中心GPU和SoC的标配。当下业内正在开发的DRAM-on-Logic堆叠方案,有望将AI芯片带宽进一步提升至32TB/s,使得AI大模型应用响应速度进一步加快,更接近人类直接交流。然而, 3D堆叠技术虽然能解决AI芯片内存墙的问题,却也需要面对从2D到3D芯片设计方法转变的挑战。

李玉童详细介绍了封装级3D-IC和晶圆级3D-IC(3D-SoIC/X-Cube)、同构与异构3D-IC等3D-IC路线图和挑战。如果将多个2.5D、3D封装的芯片堆叠到同一个系统级芯片封装中,就得到了所谓的3.5D-IC。从2.5D到3D-IC乃至3.5D- IC,对于AI芯片而言,无论是带宽,还是处理单位数据的能效比所带来的优势都是无与伦比的。同时,因为芯片堆叠产生了与堆叠的不同组件和整个系统相关的新复杂性,该技术也在三维芯片架构和系统规划,不同层间的键合策略选择,传输层和运算层的Bump对齐、时钟树协同优化,以及系统层次的STA、IR-Drop、Thermal、LVS等方面带来新的挑战。

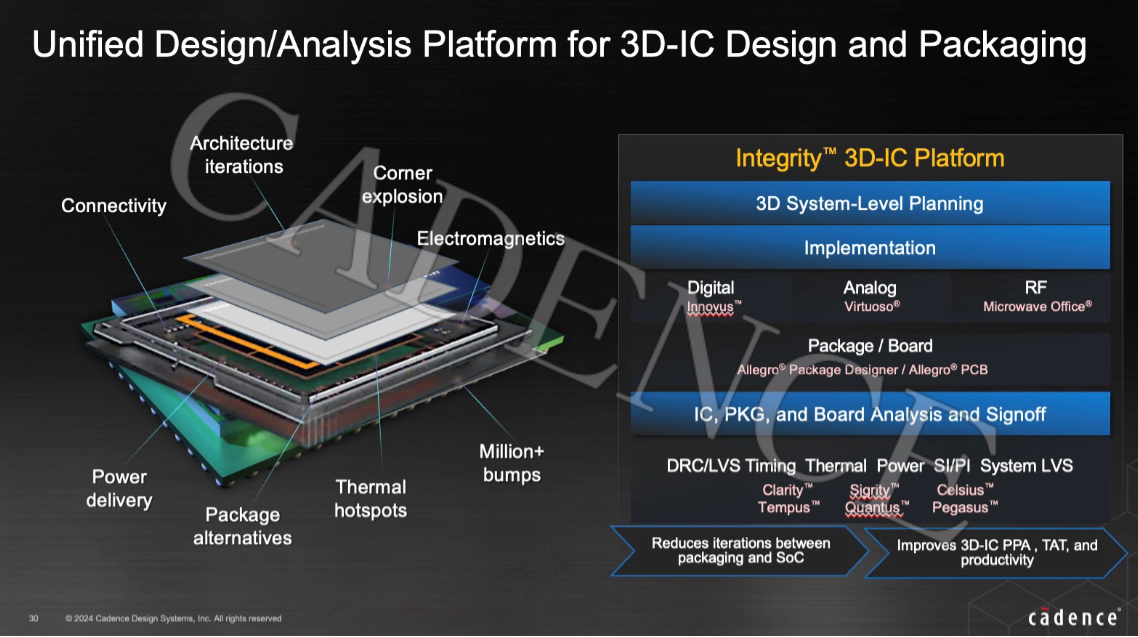
李玉童强调,随着摩尔定律逐渐失效,晶圆级3D-IC已成为行业的焦点,3D-IC的先进性将极大地丰富系统公司从系统方面提升芯片性能的手段。Cadence自2018年起就专注于各种类型的同构异构集成技术,成为业内首个推出从芯片到系统完整解决方案的EDA公司,并推出了业界首个高性能高集成度的Cadence® Integrity™ 3D-IC Platform平台,整合了系统规划、封装和设计流程早中后期系统级分析功能,可提供芯片上(on-chip)以及芯片外(off-chip)的跨芯片的时序分析、供电网络规划、IR和热分析以及不依赖第三方规则文件的系统级LVS/DRC物理验证,帮助系统设计师从3D-IC项目初期规划、分析三维芯片系统的堆叠方案选择(2.5D/3D, Face2Face/Face2Back/Back2Back),并利用多物理场系统分析技术,基于不同阶段项目参考库文件和网表从零到100%的不同完成度,探索、分析、迭代及决策3D-IC最佳系统架构。

正是基于上述前瞻性研发布局,使得3D-IC设计实现团队有充裕的三维物理时序功耗设计裕量进行跨芯片并行数字后端实现,并无缝调用Cadence的Virtuoso®和Allegro®模拟和封装实现平台进行协同设计。
最后,李玉童分别通过客户同构设计、异构设计芯片的流片项目为例,详细阐述了在一个完整的设计流程内如何通过该平台来进行热分析、功耗分析、裸片间静态时序分析和物理验证,优化系统性能。他强调,3D-IC技术的发展将为高带宽AI芯片的性能提升带来革命性的变化,Cadence将通过不断创新和优化其设计平台,致力于帮助客户克服技术挑战,实现更高的产品性能和市场竞争力。
基于标准的协议对未来人工智能工作负载至关重要

在分论坛上,李志勇首先分析了AI时代的市场趋势和关键驱动因素,以及生成式AI对半导体行业的重大影响。在不同的AI应用中,对处理器和SoC的需求各不相同,不同的工作负载需要不同的系统构成。李志勇指出,无论是推理、训练、数据挖掘或图形分析,异构应用都需要非常独特的解决方案才能优化实施。这些技术使用不同的系统架构和资源,在HPC/AI领域并不存在一种适合所有情况的最佳系统架构。也正是因此,面对不同AI应用需求的各类AI处理器和SoC架构将面临前所未有的设计挑战。

首先,数据传输设计是关键,通用设计的复用将带来增量性能和成本方面的优势,包括计算、内存和I/O等。其次,标准接口是设计的关键组成部分。当前市场上的各类主流及创新架构均大量使用了各种标准接口,HPC、AI/ML和云对各类IP的需求正在不断增加。最后,随着摩尔定律来到极限,以UCIe和其他形式实现的D2D接口的封装和标准化方面的进步使分解和基于芯粒的设计正在成为现实。
Cadence通过不断创新和优化全栈IP解决方案,帮助客户克服AI芯片设计挑战。
在存储接口方面,Cadence的协议选项涵盖先进技术节点中所有最新标准和数据速率的深度解决方案组合,包括DDR、LPDDR、GDDR、HBM等,可帮助客户利用多功能内核以更快的速度完成更多任务,全面满足客户从存储到AI,再到图形和内存扩展器的各种应用需求。

在高速串行接口方面,Cadence是唯一一家拥有8通道Gen6控制器和PHY测试芯片的IP提供商,同时,Cadence在PCIe 7也将保持领先,Gen7已经向客户演示了demo,并有望在2027年满足市场需求。

在高速以太网方面,Cadence的解决方案包括业界领先的224G/112G/56G物理层IP和控制器IP,可支持高达800G/1.6T的子系统,还展现出卓越的硅性能,在Cadence测试芯片和客户生产芯片中均已得到验证。
与此同时,随着Chiplet成为后摩尔时代的共识,D2D接口IP需求迅速增加。Cadence已推出使用 UCle 标准接口实现处理器、系统IP 和内存 IP 的高效集成解决方案,可满足高性能计算、汽车和数据中心行业不断变化的需求,并帮助客户克服设计挑战并加快产品上市时间。









