6月16日至6月20日,超大规模集成电路研讨会(Symposium on VLSI Technology and Circuits,简称VLSI)在美国夏威夷成功举办。本次大会,学院部分师生参会展示成果,并在会上与各国顶尖学者进行了充分的交流。在本届VLSI大会上,北京大学集成电路学院/集成电路高精尖创新中心有3篇高水平论文入选,向国际同行展示了相关方向的最新研究成果。上述3篇论文内容涉及新型超微缩倒装堆叠集成技术、异构领域定制AI SoC芯片、超高速大摆幅收发机芯片等前沿领域。论文的详细内容如下:
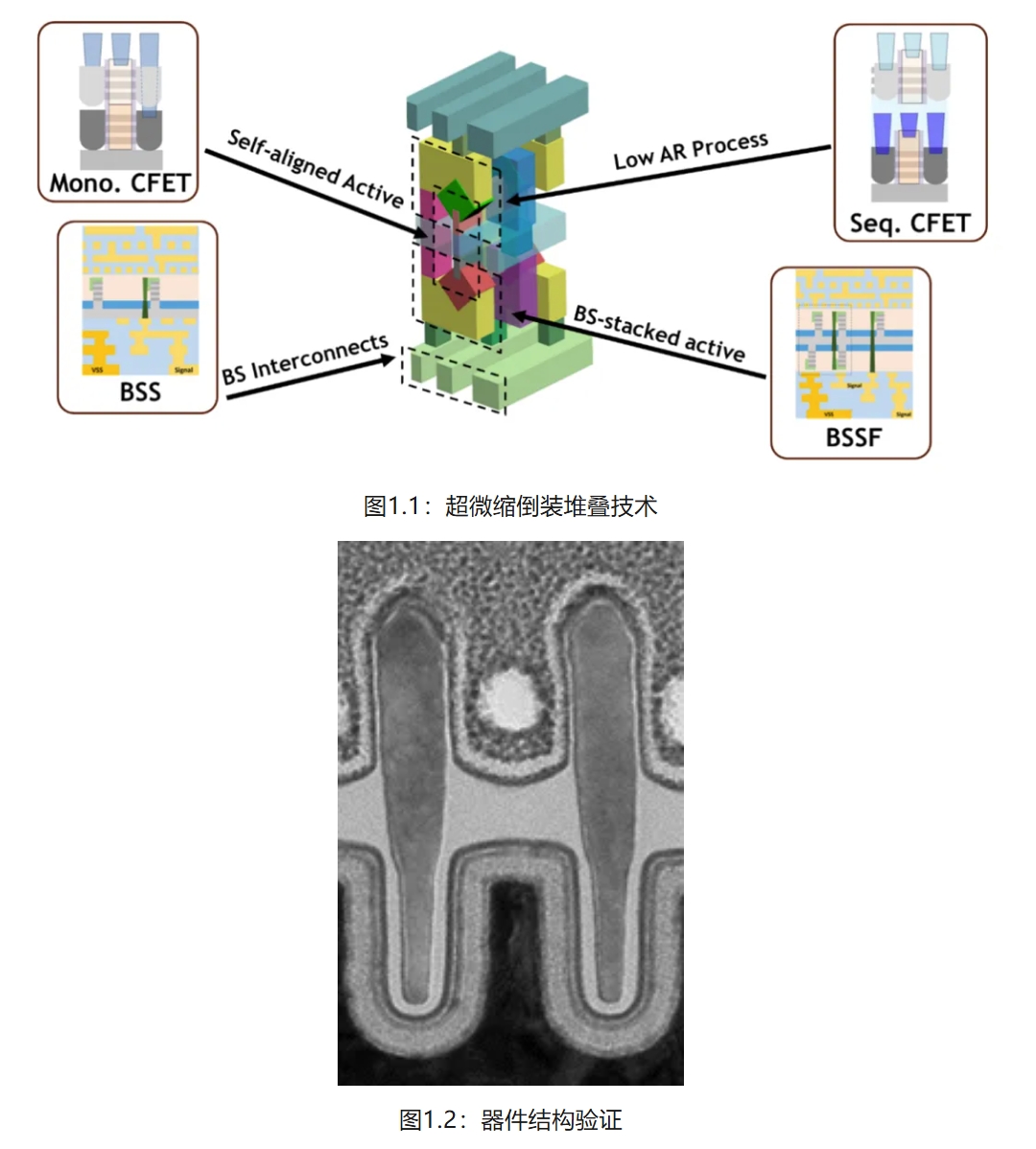
一、
新型超微缩倒装堆叠集成技术
集成电路先进制造技术正在向多层面的三维集成加速演进。在器件层面,CFET等堆叠晶体管技术(stacked transistor technology)被广泛讨论;在互连层面,晶圆背部互连正逐步被业界采纳。然而,当前CFET器件技术受制于大深宽比工艺和复杂制造流程,实际应用面临巨大挑战。针对上述技术难点和发展趋势,黄如院士团队的吴恒研究员等人等提出了一种新型超微缩倒装堆叠晶体管技术(Flip FET),其充分利用晶圆背部进行晶体管级三维堆叠,有效地融合了晶圆背部互连和堆叠晶体管集成方法,可以极大提升芯片集成密度和电路设计灵活度。同时,制造流程可复用FinFET和当前主流的背部互连工艺,并且可有效克服当前CFET技术面临的大深宽比工艺和分离栅(Split Gate)实现难点,为超越下一代堆叠器件提供了新思路。
该工作以“ First Experimental Demonstration of Self-aligned Flip FET (FFET): a Breakthrough Stacked Transistor Technology with 2.5T Design, Dual-side Active and Interconnects ”为题发表,是今年VLSI会议在先进逻辑领域国内唯一录用论文,第一作者是集成电路学院博士生卢浩然,通讯作者是吴恒研究员。
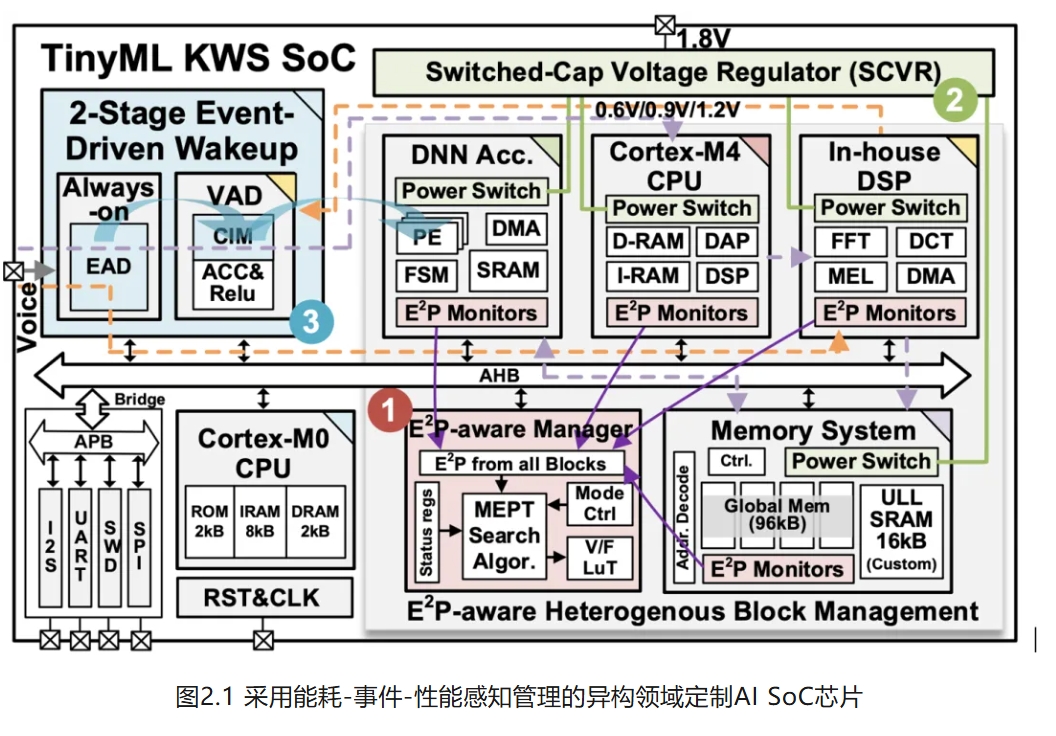
二、
采用能耗-事件-性能感知管理的异构芯片
异构SoC通常包括微处理器CPU和多个领域专用加速器(DSA),例如深度学习加速器。多样化的机器学习工作负载和异构架构对低功耗管理提出了挑战,即如何智能地在异构块中分配能耗,以端到端的角度获得系统级最小能量点。
针对以上问题,黄如院士-叶乐教授、贾天宇研究员团队等提出了一种具有端到端能耗-事件-性能感知的系统级电源管理的异构TinyML SoC,实现了最低3.5µW和30000倍的峰值到空闲功耗比。这种端到端性能感知管理利用各种完全可综合的监视器来了解异构块的运行状态,并使用层次化的电压调节进行系统级的最小能量点搜索,相比于单一块的最小能量点,能节省超过28%的能耗。团队还开发了一种基于存内计算的两阶事件驱动唤醒方案,以减少超过87%的常开能耗。
该工作以“A Heterogeneous TinyML SoC with Energy-Event-Performance-Aware Management and Compute-in-Memory Two-Stage Event-Driven Wakeup”为题发表,文章第一作者是北京大学博士生董彦池,通讯作者贾天宇研究员和叶乐教授。
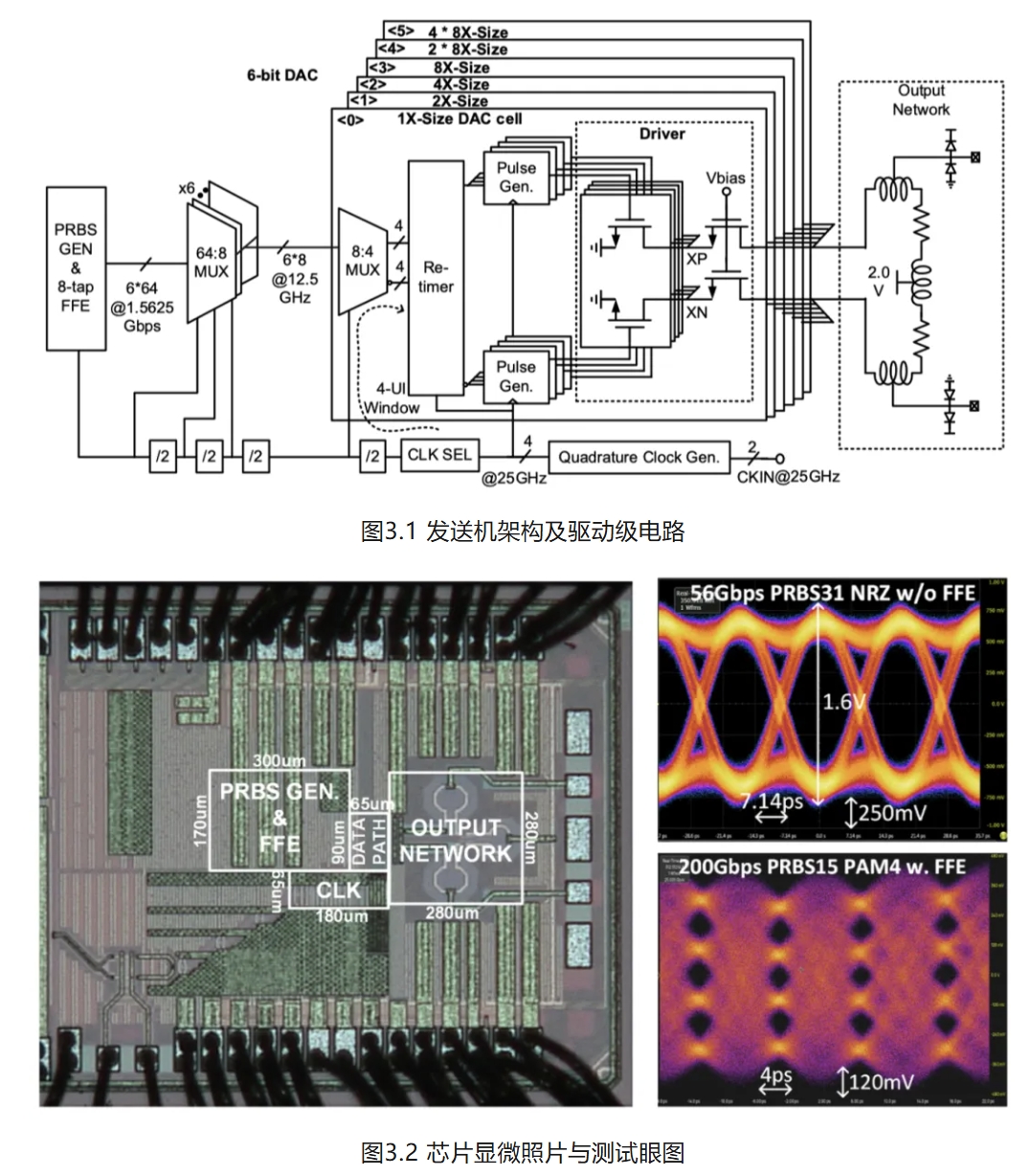
三、
超高速大摆幅CMOS发送机芯片
人工智能,大数据运算等技术的快速发展对以太网通信所需的光模块产品提出更高的要求。传统光模块依赖基于SiGe工艺的独立驱动器芯片将数字基带信号放大至激光调制器所需的大摆幅,但引入了较大的功耗,同时限制了数据传输速率的提升和光模块的进一步集成化。
针对该问题,盖伟新教授团队研制了一款基于CMOS工艺的超高速大摆幅发送机芯片,研究并提出了一种新型驱动级电路,提高电路耐压范围的同时减小负载,提升驱动级电路带宽;同时,设计了一种低抖动脉冲发生器电路,将脉冲信号边沿抖动压缩至类似工作的十分之一以内。此外,团队还研制了一种高精度正交时钟产生电路,能够检测和校准多种超高速多相时钟所面临的相位误差。基于以上技术,团队采用12nm CMOS工艺完成了流片验证,并进行了性能测试和汇报。发送机芯片数据速率达到200Gb/s,驱动摆幅达到1.6Vppd,与已有的200G CMOS发送机相比实现了最大的驱动摆幅,驱动级电路功耗与SiGe驱动器芯片相比仅为15%,达到了国际领先水平。