

1、ASML第一季度营收53亿欧元 净利润12亿欧元
2、市场观察人士:台积电或上调今年营收和资本支出预期
3、算力网络IO大战:以太网与IB双雄对决 UEC搅局
4、三星即将量产290层V-NAND闪存
5、日本3月出口额连续增长,半导体等电子零部件增幅11.3%
6、Microchip收购Neuronix人工智能实验室,增强FPGA部署效能
7、3M预计CMP抛光垫收入3年内将增长300%
1、ASML第一季度营收53亿欧元 净利润12亿欧元

集微网消息,4月17日,荷兰半导体设备商ASML公布的财报显示,该公司第一季度销售额为53亿欧元,毛利率51.0%,净利润12亿欧元。第一季度新增订单额为36亿欧元,其中6.56亿欧元为EUV光刻机订单。
ASML预计,2024年第二季度净销售额将在57亿欧元至62亿欧元之间,毛利率将在50%至51%之间,2024年的净销售额将与2023年基本持平。
ASML总裁兼CEO Peter Wennink表示:“我们第一季度的销售额为53亿欧元,处于我们预测营收区间的中间值,毛利率为51.0%,高于预期目标,主要得益于不同产品组合和非经常性的一次性费用。我们预计第二季度净销售额在57亿欧元至62亿欧元之间,毛利率在50%至51%之间。ASML预计研发成本约为10.7亿欧元,SG&A(销售、一般和管理费用)成本约为2.95亿欧元。随着半导体行业从低迷状态中持续复苏,我们对2024年全年的展望保持不变,预计下半年业绩将比上半年强劲。我们视2024年为调整年,公司将继续在产能提升和技术方面进行投资,为迎接行业的周期拐点做好准备。”
2、市场观察人士:台积电或上调今年营收和资本支出预期

集微网消息,台积电的估值在飙升至历史高点后仍处于平淡的水平,该公司即将公布的业绩有可能进一步推高其股价。市场观察人士认为,在上一季度销售好于预期之后,台积电有可能上调今年的营收和资本支出预期,这证明人工智能推动的强劲增长将持续下去。
作为英伟达等公司设计的芯片的主要制造商,台积电被视为人工智能热潮的主要受益者。虽然目前智能手机和其他消费产品的前景仍不明朗,但该行业不断升级到更精细的电路是另一个积极因素。
澳新银行投资总监Xin-Yao Ng表示:“最值得关注的是台积电的资本支出预期,因为这往往是他们所看到的需求的一个指标。我们仍然认为台积电值得买入,因为其股价上涨受到基本面因素的支撑,他们在最先进芯片节点上的主导地位和技术领先地位,使他们处于非常有利的地位,可以在更长时间内以高速度复合盈利。”
据悉,台积电股价较2022年10月的低点上涨了一倍多,市值增加了3300亿美元。不过,该股目前的股价略低于5年估值中值,为明年预期收益的16倍。相比之下,费城半导体指数的市盈率超过28倍,创15年新高。
台积电将于4月18日公布第一季度的业绩,从中可以了解到各业务的销售贡献,以及该公司在海外扩张方面的盈利能力如何。分析师估计,台积电第一季度的毛利率将保持在53%,与上一季度持平。
台积电目前的2024年全年资本支出预算为280亿至320亿美元,预计其收入将至少增长20%,扭转2023年的小幅下滑趋势。分析师的普遍预测是290亿美元。该公司正在进行在美国、日本和德国建厂的项目,以满足全球需求。
晨星公司分析师Phelix Lee表示:“台积电被低估了,因为该公司在尖端芯片领域的主导地位有时被地缘政治风险所掩盖。最近有消息称台积电根据美国芯片法案为亚利桑那州的工厂获得了116亿美元的赠款和贷款,这些担忧得到了部分解决。”
盛宝银行股票策略主管Peter Garnry称:“我们预计,需求和销售增长将比目前反映在股价中的水平持续更长时间。当然,一个负面因素是随着资本支出需求增加,自由现金流降低,其制造业基地越来越需要冒险离开中国台湾。”
3、算力网络IO大战:以太网与IB双雄对决 UEC搅局
集微网报道 在AI大模型引发的算力就是生产力的时代,围绕GPU和HBM的角逐看似趋于明朗,但一场新的暗战却在积蓄力量,有可能成为左右战局的新筹码。
传奇CPU大神兼Tenstorrent首席执行官Jim Keller在前几天发布的微博简明扼要指出算力系统中有IO、存储和计算三大关键,而以太网将赢得IO之战不久,他又用心良苦直接建议英伟达使用以太网,而不是InfiniBand(IB)。
如果笔者理解无误,Jim Keller说的以太网应该指的是RoCE,但意欲超越RoCE的超以太网联盟UEC于去年年中成立。而英伟达独享的IB会像CUDA一样,遭受光明顶式的围攻吗?

三类技术竞逐网络IO
随着训练模型规模的指数级增长,支撑AI算力的分布式集群网络规模也日益扩大。有分析称,AI模型每隔两到三年将增长1000倍,目前的数据中心交换机市场支出主要用于连接通用服务器的前端网络,AI工作负载将需要建立新的大量的后端网络。由此多台服务器之间的互联通信速率成为影响训练表现的关键因素,提升算力效率、构建高性能网络也成为大厂们新的练兵场。
传统以太网主要采用TCP/IP来构建,但在生成式AI时代显然“难合时宜”。由于其需要数据发送方将数据多次复制到内核,然后再通过网络发送到接收方,接收方接收数据后还需要再次进行内存复制和处理,这一系列操作导致了较高的延迟,通常在毫秒级别,这对于需要低延迟的多机多卡网络来说显然不如人意。
在此情形之下,RDMA(远程直接内存访问技术)应运而生。作为一种高效的网络互联技术,它允许数据在网络中的两个节点之间直接传输,而不需要内核的参与,所有的传输处理都由NIC(网络接口卡)硬件来完成,不仅降低了对计算资源的占用,还大大提升了数据传输的速率。
目前来看,RDMA有三类主要技术实现方式。
相关资料显示,英伟达中意的Infiniband(IB)作为一种高性能的互联技术,从一开始就内置了RDMA的支持,能够实现节点之间的高速直接内存访问和数据传输,具有极高的吞吐量和极低的延迟。RoCE(RDMA over converged Ethernet)则是在以太网上实现RDMA的技术,它使用标准的以太网作为基础传输介质,并通过RDMA适配器和适当的协议栈来实现RDMA功能。iWARP则是基于TCP/IP协议栈的RDMA实现,它使用了普通的以太网适配器和标准的网络交换机,并通过在TCP/IP协议栈中实现RDMA功能来提供高性能的远程内存访问和数据传输。
由于RoCE和IB自带不同的“基因”,也呈现出相异的优劣势。IB网络作为一种原生的RDMA网络,在无拥塞和低延迟环境下表现卓越,以其高可靠性、低时延、高带宽等特点在超级计算机集群中得到广泛的应用。此外,随着AI大模型的指数级进化,尤其是英伟达在GPU的绝对垄断地位,也让IB成为GPU服务器的首选网络互连技术。
而RoCE凭借其依托成熟的以太网生态、最低的组网成本以及最快的带宽迭代速度,在中大型训练GPU集群的场景中展现出更高的适用性。其突出的优势在于用户从以太网切换到RoCE,只需购买支持RoCE的网卡,其他网络设备都是兼容的。目前这一阵营已拥有AMD、博通、英特尔、Meta、微软和甲骨文等巨头。
相对来说,iWARP的协议战相对更复杂,而且由于TCP的限制,它只能支持可靠传输,这也导致了iWARP的发展速度不如RoCE和IB。
两强相争天平倾向以太网?
尽管IB自带强者风范,但其隐忧也在深藏。
由于IB重新设计了物理链路层、网络层、传输层,从链路层到传输层都无法与现有的以太网设备兼容,想要切换或扩容,成本均过于高昂。如某数据中心想要将数据交换方式从以太网切换到IB的技术,那么需要购买全套的IB设备,包括网卡、线缆、交换机和路由器等。此外在构建大规模的AI集群时,如果节点数量超过了IB网络的扩展能力,由于IB的可扩展性差,不仅会增加扩建成本,也对日后的流量管理、其他服务集成造成麻烦,甚至会影响IB的低延迟性能。
据相关数据显示,网络一般占集群成本的20%。尽管黄教主言之凿凿,说IB在相同带宽下的大规模性能比以太网高出 20%,因此IB实际上是免费的。但客户仍要拿出真金白银,在承受了GPU的溢价之后,还要承接IB高成本的暴击。
看起来尽管性能优异,但IB显然更适合于中小规模网络布局。而RoCE则完美地避开了这一“硬伤”,相对更受大厂的青睐。
市场还是会用“大脑”投票的。最近有报道称,OpenAI和微软计划用千亿美金打造一款名为“Stargate”的超级计算机。在选择网络方案时,即便微软是Infiniband的用户,OpenAI还是更加倾向使用以太网电缆而不是Infiniband电缆(简称IB),让AI行业巨头弃用成熟的IB选择以太网的原因也在于IB成本过高,可扩展性不足。
有分析指出,虽然大部分市场需求将来自一级云服务运营商,但预计2/3级和大型企业的需求量将很大,以头部公司为例,除了微软以外,亚马逊、Meta、腾讯这些头部公司机器学习场景用的都是以太网而非IB。当Stargate这么大规模的AI集群搭建也选择以太网技术,已然表明了大厂们对以太网的青睐。
一位行业人士分析,不可否认,目前IB依旧是AI厂商构建网络的主要选择,但是对比IB,以太网低成本、易扩展、不易被厂商绑定的优势愈发明显。对于考虑部署网络的AI厂商来说,选择跟随大厂一起选择以太网,根据市场需求不断实现技术的更新迭代,显然会比选择大笔资金入手IB更为划算。
此外,技术的进阶来看,以太网也更为“到位”。随着AI网络加速向更高速度过渡,预计到2025年,AI后端网络大部分端口将达到800G,而以太网的速度已可实现每秒800G,而IB的速度为400G,这让以太网技术可更好地满足AI发展需要的“理念”。
据Dell’Oro 的预测,在AI后端网络中部署的交换机支出将使数据中心交换机市场扩大50%,IB和以太网之间的竞争正在加剧。虽然IB预计将保持领先地位,但以太网预计将取得实质性进展,到2027年收入份额将增加20%,3年内收入份额翻番,留给以太网的未来发展空间可观。
UEC成为搅局者?
而在IB和RoCE明争暗斗之际,一个新的搅局者超以太网联盟UEC却已横空出世,其目标是超越现有的以太网功能,为高性能计算和AI提供高性能分布式和无损传输层。
目前这一阵营云集了博通、Cisco Systems等芯片厂商,云巨头中的微软和Meta以及交换机厂商中的 Cisco、HPE和Arista Networks。
UEC认为,几十年前定义的RDMA在要求极高的人工智能和机器学习网络流量中已过时,RDMA以大流量块的形式传输数据,可能导致链路不平衡和负担过重,是时候为新兴应用构建支持RDMA的现代传输协议了。
据了解,UEC传输协议正在开发中,旨在提供比现有的RDMA更好的以太网传输,仍支持RDMA的同时保留以太网IP的优势。UEC传输是一种靠近传输层的新形式,它有一些语义调整拥塞通知协议,并且增强了安全功能。UEC将提供更灵活的传输,不需要无损网络,允许many to many人工智能工作负载所需的多路径和无序数据包传输等功能。
目前,UEC 正处于开发的早期阶段,关键技术概念仍在确定和研究中。据了解,第一批批准草案或准备就绪,第一批基于标准的产品也预计将于今年推出。
看起来Jim Keller有些“忠言逆耳”的意味,但黄教主会改弦易辙吗?上述行业人士认为,技术都会有利弊和周期,如果太贵、割裂和独吃的话,就一定会给替代技术以市场。
而当IB和RoCE争霸之际,以UEC为代表的新兴传输协议又会带来怎样的变局?届时是一统天下还是三足鼎立?
4、三星即将量产290层V-NAND闪存

集微网消息,据韩国业界消息,三星最早将于4月开始量产当前业界密度最高的290层第九代V-NAND(3D NAND)闪存芯片,这是继236层第八代V-NAND之后的又一重大进步,是当前业界可量产的最高堆叠层数。此外,三星计划在2025年推出430层V-NAND产品。
业界人士表示,三星此举旨在满足人工智能(AI)热潮下对于NAND闪存的需求。随着人工智能领域从“训练”转向“推理”,需要处理大量数据,如图像和视频,因此需要大容量存储设备。观察人士还指出,三星对于其NAND业务在第一季度的盈利比较乐观。
三星即将推出的第九代V-NAND采用双层键合技术提高生产效率,打破了业内专家的预测,此前曾认为要达到300层,需要三层键合技术。
研究机构TechInsights预测,三星将在2025年下半年量产第十代V-NAND,可达430层,直接跳过350层。
5、日本3月出口额连续增长,半导体等电子零部件增幅11.3%

集微网消息,根据日本财务省的官方数据,日本3月出口额实现连续4个月同比增长,增幅7.3%,出口总额达到9.46万亿日元(约合610亿美元);进口总额9.1万亿日元,同比下降4.9%。这也是日本3个月来首次出现贸易顺差。
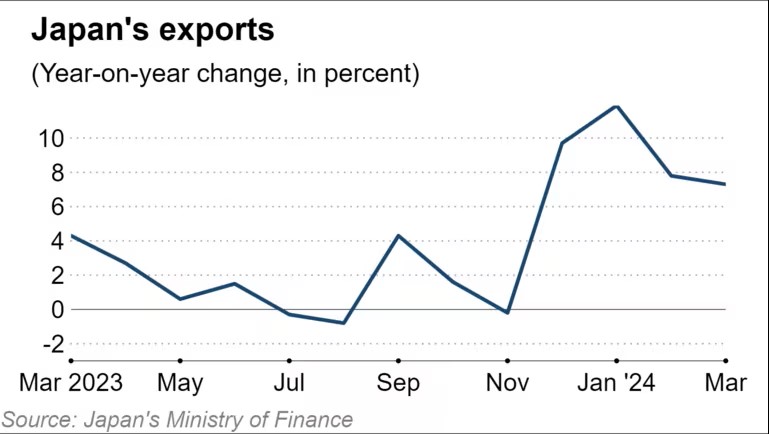
3月日本汽车出口额同比增长7.1%,半导体在内的电子零部件出口额增长11.3%;燃料方面,煤炭进口下降35.1%,液化天然气进口下降9.5%。
按照出口目的地划分,日本3月对中国出口额同比增长12.6%,达到1.74万亿日元;对美国出口额同比增长8.5%;对欧盟出口额增长3%。
业界表示,日本整体出口数据的增长是由于价格攀升,而非全球需求增长。按照数量统计,受到对欧盟和亚洲货物出口量的减少,3月日本出口总量下降2.1%,进口总量下降9.4%;对中国出口量同比增长0.9%;对美国出口量同比增长1.8%。
根据日本央行近日公布的初步数据,日本3月出口产品价格比去年同期上涨8.5%,整体进口产品价格上涨1.4%,但石油、煤炭和天然气的进口价格下降6.9%。
6、Microchip收购Neuronix人工智能实验室,增强FPGA部署效能

集微网消息 4月15日,Microchip (微芯科技公司)宣布收购 Neuronix AI Labs,以进一步增强在现场可编程门阵列(FPGA)上部署高能效人工智能边缘解决方案的能力。Neuronix AI Labs提供神经网络稀疏性优化技术,可在保持高精度的同时,降低图像分类、目标检测和语义分割等任务的功耗、尺寸和计算量。
Microchip的中端PolarFire® FPGA和SoC在低功耗、可靠性和安全功能方面已处于行业领先地位。完成此次收购后,Microchip将能在成本、尺寸和功耗受限的系统上开发出经济高效的大规模边缘部署组件,用于计算机视觉应用,并使中低端FPGA的AI/ML处理能力成倍增强。
Microchip负责FPGA业务部的公司副总裁Bruce Weyer表示,收购 NeuronixAI Labs的技术将提高Microchip在采用AI/ML算法的智能边缘系统中部署的FPGA和SoC的能效。Neuronix的技术与Microchip的VectorBlox™设计流程相结合,可提高神经网络的性能效率,并在低功耗PolarFire FPGA和SoC中实现出色的 GOPS/watt 性能。系统设计人员现在能够设计和部署以前由于尺寸、散热或功耗限制而难以构建的小尺寸硬件。”
Neuronix AI Labs首席执行官Yaron Raz表示:“Neuronix AI Labs一直致力于开发一流的神经网络加速架构和算法,以满足用户对尺寸、功耗、性能和成本的预期。加入Microchip团队为我们提供了独特的机会,使我们能够扩大规模,并与在功耗效率方面树立了行业标准的FPGA 产品组合保持一致。”
收购这项技术后,非FPGA设计人员无需深入了解FPGA设计流程,即可使用行业标准人工智能框架,利用强大的并行处理能力。Neuronix人工智能知识产权与Microchip现有的编译器和软件设计工具包相结合,可以在可定制的FPGA逻辑上实现AI/ML算法,无需RTL级专业知识或对底层FPGA结构的深入了解。它还允许即时更新和升级CNN,无需对硬件重新编程。
值得一提的是,4 月 11 日,Microchip 宣布完成对总部位于韩国首尔的 VSI 公司的收购,其中 VSI 公司是汽车行业先驱,提供基于汽车 SerDes 联盟(Automotive SerDes Alliance,ASA)车载网络(IVN)开放标准的高速非对称摄像头、传感器和显示连接技术和产品。该交易条款尚未披露。
7、3M预计CMP抛光垫收入3年内将增长300%
集微网消息,3M公司近日设定目标,未来3年内化学抛光垫(CMP)的销售收入将增长300%。

3M公司韩国电子材料技术主管Yang Yong-suk在一次活动中表示,先进节点的晶体管正在向纳米级发展,但CMP抛光垫冲击晶圆表面的结果仍难以预测。他表示,为了解决这个问题,3M的抛光垫设计了尖角和开孔,以保证对整个晶圆均匀接触。
据悉,在芯片生产中,需要在晶圆上进行20到40步CMP工艺,在这个过程中抛光垫和研磨液会对晶圆进行抛光。
3M是CMP市场的后起之秀,于2018年推出首款产品。杜邦公司是该领域领导者,此外还有韩国公司SK Enpulse,向SK海力士供应此类产品。
3M公司开发了“微复制”(micro-replicated)CMP抛光垫,这种产品表面粗糙,有着像抛光前的晶圆一样的微小凸起或者凹陷。Yang表示,其竞争对手的产品需要用金刚石磨盘不断打磨以保证其粗糙度,但这也会导致其表面不断变化。相比之下,3M的CMP抛光垫能够自始至终保持相同的表面积。
业界表示,3M公司的产品可能主要针对10nm及以下工艺。3M称,其产品抛光效率提高了30%,寿命是竞争对手的1.5~2倍。







