
2026年6月14日至18日,IEEE/JSAP超大规模集成电路技术与电路国际研讨会(IEEE/JSAP Symposium on VLSI Technology and Circuits, VLSI Symposium)在美国夏威夷檀香山举行。VLSI是国际半导体与集成电路领域的顶级学术会议之一,与国际固态电路会议(ISSCC)、国际电子器件会议(IEDM)并称为领域最具影响力的国际会议,是国际学术界和产业界发布前沿芯片技术与半导体创新成果的重要平台。
华中科技大学集成电路学院缪向水/李祎团队研究成果“A 40nm 24.85-to-80.59 TFLOPS/W FP8 Computing-in-Memory Macro with Outlier-Aware Hierarchical-Alignment for Edge Transformers”入选VLSI 2026并发表。该论文提出了一种面向端侧Transformer推理的40 nm FP8浮点存算一体(Compute-in-Memory, CIM)芯片宏单元,为高精度、高能效端侧智能计算提供了新的硬件实现路径。集成电路学院博士研究生周志威、胡同为论文的共同第一作者,李祎教授、陈佳副教授为论文共同通讯作者,集成电路学院为第一完成单位。
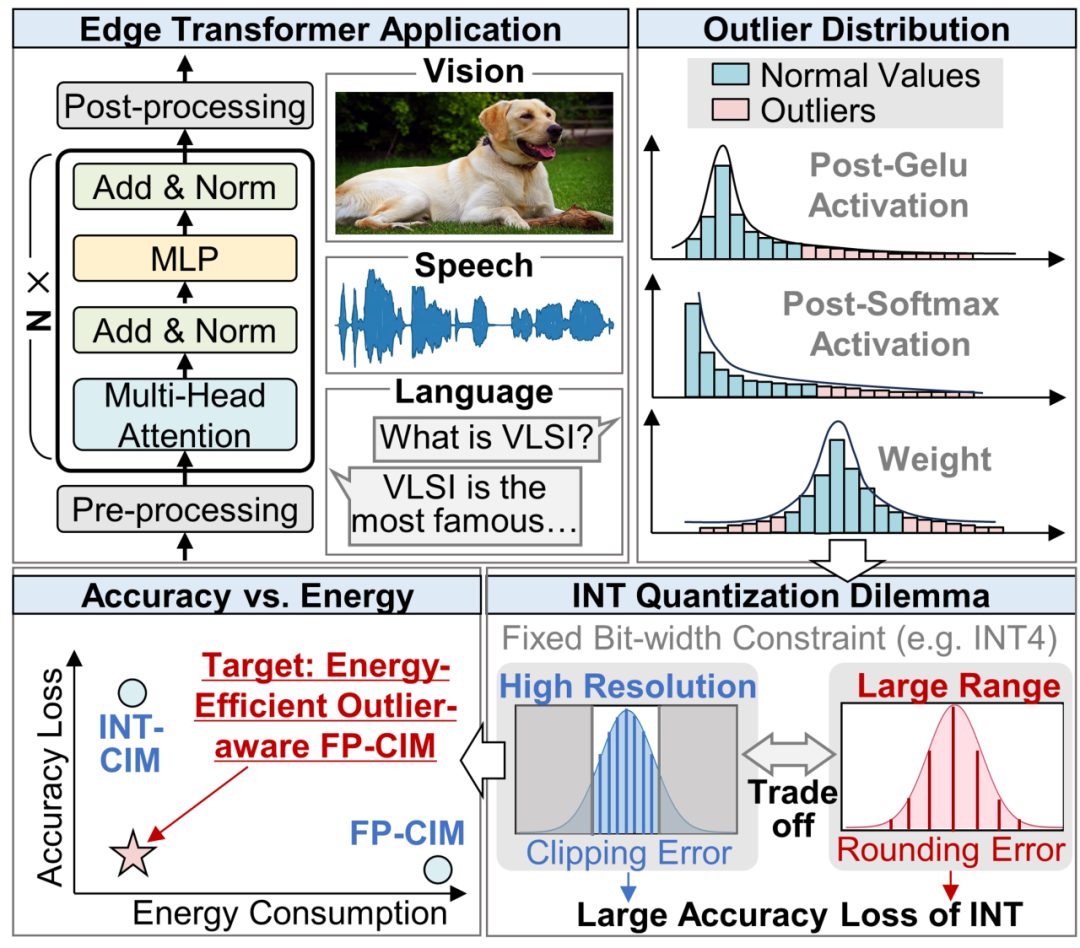
图1 端侧Transformer中的离群值分布
近年来,Transformer模型在视觉、语音和自然语言处理等端侧智能应用中展现出优异性能,但其大规模矩阵运算和显著的离群值分布对芯片能效与计算精度提出了更高要求。传统整型存算一体方案虽然具有较高能效,但在面对Transformer激活值和权重中的离群值时容易出现裁剪或舍入误差,造成明显精度损失。浮点存算一体技术能够提供更大的动态范围,是支撑高精度端侧Transformer推理的重要方向。然而,现有浮点存算一体方案通常面临“精度—能效”权衡:预对齐方案硬件开销较低但精度受限,后对齐方案精度较高但移位和宽位宽累加带来较大的面积与能耗开销。
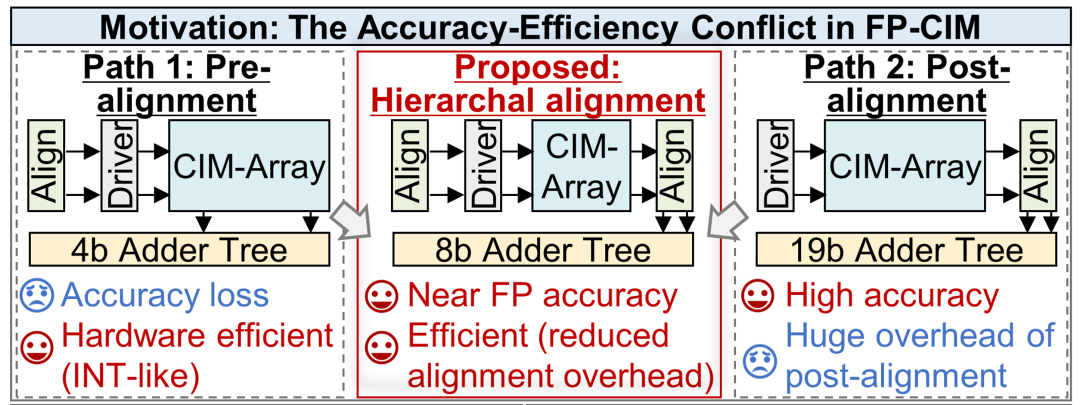
图2 浮点存算一体设计挑战
针对上述挑战,团队提出了离群值感知的层级对齐浮点存算一体架构。首先,层级双指数对齐(Hierarchical Dual-Exponent Alignment, HDEA)方法将离群值与普通值分离处理,使普通值对齐到中间指数域、离群值对齐到最大指数域,从而在保持接近理想浮点精度的同时显著限制累加位宽增长。其次,原码输入串行流水对齐器(Sign-Magnitude Input Serial Pipelined Aligner, SMSPA)将指数查找、指数差计算和尾数移位串行流水化,缓解传统并行对齐与位串行乘加之间的流水停顿问题,降低对齐逻辑的面积和功耗。第三,移位拼接符号反转加法树(Shift-Concat based Sign-Inverse Adder Tree, SSAT)通过减少冗余符号扩展和无效翻转,进一步降低浮点后处理累加开销。
测试结果表明,该FP8存算一体宏单元可在0.8-1.1 V供电电压、100-326 MHz工作频率下稳定运行,FP8计算能效达到24.85-80.59 TFLOPS/W。与已有后对齐浮点CIM方案相比,该芯片宏单元在保持多类任务高精度的同时,实现了最高6.66倍的能效提升。相关结果表明,该工作有效缓解了浮点CIM中长期存在的精度、面积与能效权衡问题,为端侧Transformer和未来低功耗智能芯片的部署提供了高效硬件支撑。
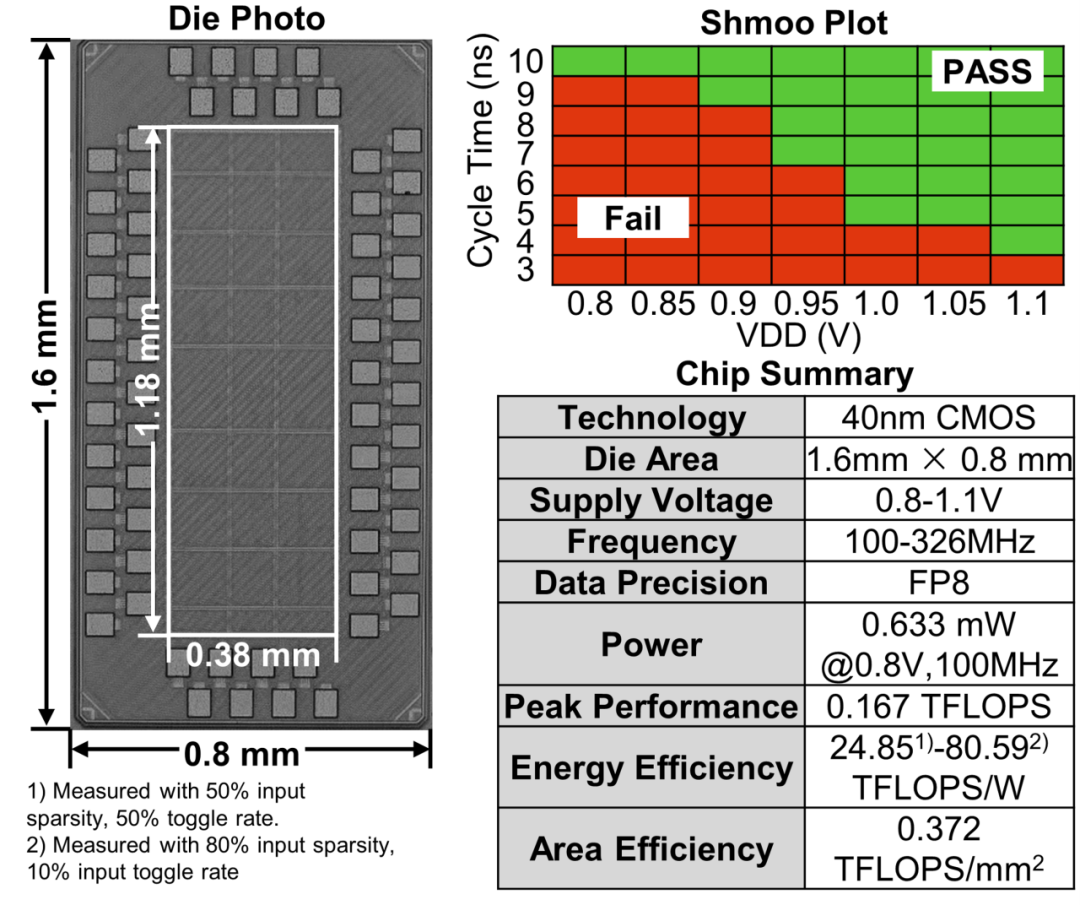
图3 浮点存算一体宏单元及关键测试指标
该研究得到国家重点研发计划、脑科学与类脑智能技术国家科技重大专项和国家自然科学基金等项目资助,并受到国家集成电路产教融合创新平台、先进存储器湖北省重点实验室等平台支持。








