
2022年12月11日,中国移动全球合作伙伴大会举办“中国移动产业链创新暨算力网络分论坛”,围绕链合创新、联创未来、算力时代,全方位展示产业链融通生态、群体性突破成果、算力网络创新成效等内容。其中,产学研各单位联合发布的行业首个《存算一体白皮书》引发强烈关注,将成为引导产学研各界规范认知存算一体及其发展的权威宝典。

《存算一体白皮书》由中国移动通信有限公司研究院牵头编写,中兴通讯股份有限公司、华为技术有限公司、清华大学、北京大学、北京知存科技有限公司、曙光信息产业股份有限公司、深圳亘存科技有限责任公司联合编写。全面阐释了存算一体的核心技术、发展路线、应用场景和产业链生态。旨在促进产学研各界凝聚共识、加强合作、协同发展,推动存算一体技术成熟和生态繁荣,加快存算一体产业化进程,助力我国在先进计算领域实现高水平自立自强。
自2022年4月白皮书启动会以来,知存科技与产业界、学术界各单位专家一同,历经逾半年的反复交流、撰写、讨论最终修订成册。其中,尽所能归纳和整理了知存科技存算一体产业化探索的先行经验和洞察。在推动行业标准化、规范化的同时,知存科技也在过程中收获了更加清晰的企业发展目标和愿景。现提炼《存算一体白皮书》部分内容做简要分享,供读者快速预览。
一、存算一体是先进算力的代表性技术
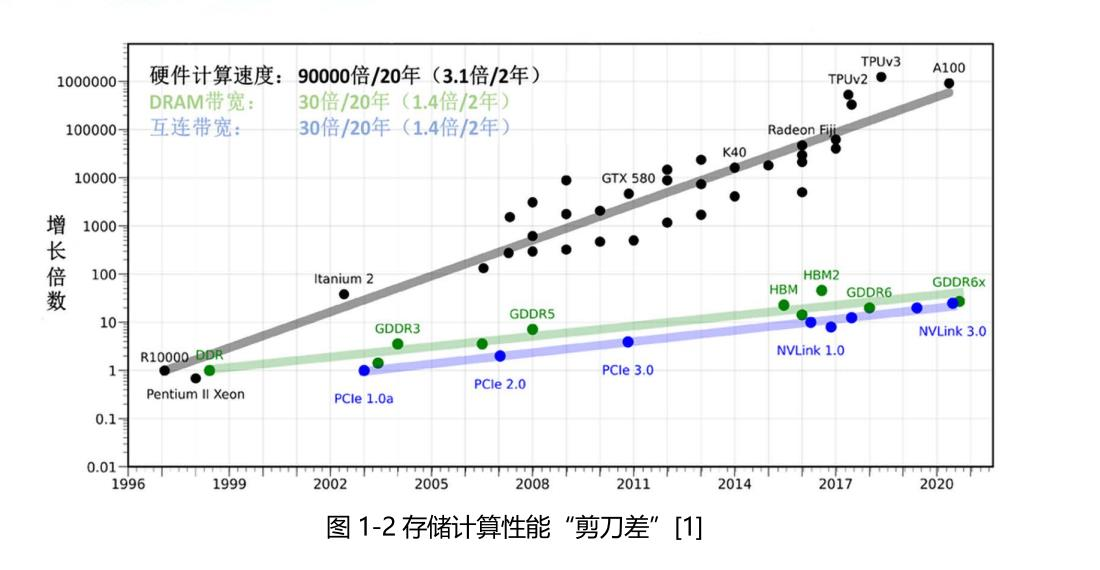
存算一体的核心是将存储与计算完全融合,有效克服冯·诺依曼架构瓶颈,并结合后摩尔时代先进封装、新型存储器件等技术,实现计算能效的数量级提升。
二、存算一体技术路线建议
白皮书将广义存算一体技术进行分类,望达成广泛共识。根据存储与计算的距离远近,将广义存算一体的技术方案分为三大类,分别是近存计算(Processing Near Memory, PNM)、存内处理 (Processing In Memory, PIM)和存内计算(Computing in Memory, CIM)。 存内计算即狭义的存算一体。在芯片设计过程中,不再区分存储单元和计算单元,真正实现存算融合。
针对存内计算存储器件,白皮书对静态随机存储器(SRAM)、NOR Flash、阻变随机存储器(RRAM)、磁性随机存储器(MRAM)、相变存储器(PCM)五种主流的存储器件及其存内计算进行了描述和对比分析。
当前NOR Flash、SRAM等传统器件相对成熟,可率先开展存内计算产品化落地推动。新型器件中RRAM各指标综合表现较好,MRAM寿命和读写性能较好,均有各自独特优势与发展潜力,可持续推动器件成熟,同步进行存内计算探索。PCM新器件成熟度相对较高,当前已可应用于近存计算研究,不过其寿命、能耗指标较RRAM无优势,预计存内计算潜力稍弱,未来可能更多作为存储器辅助存算一体整体技术发展。建议产业未来展开多路径探索,实现各方案优势互补,推动整体产业发展
三、存内计算在云边端具有广泛的应用场景
与传统方案相比,存内计算在功耗、 计算效率等方面具有明显优势,在相同制程工艺下,存内计算芯片能在单位面积下提供更高的算力,更低的功耗,进而延长设备工作时间,将在端侧具有广阔应用前景,将广泛应用于家庭网关、工业 网关、摄像头、可穿戴设备等场景。
当前存内计算产品已成功在端侧初步商用,提供语音、视频等AI处理 能力,并获得十倍以上的能效提升,有效降低了端侧成本。

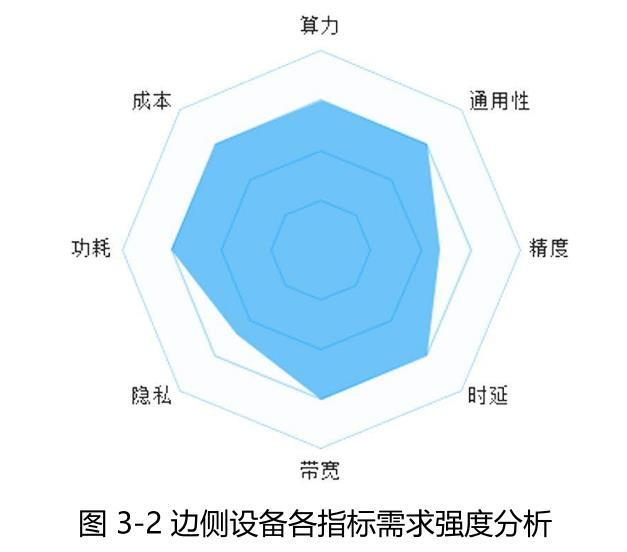
与传统方案相比,存算一体在深度学习等领域有独特优势,可以提供比传统设备高几十倍的算效比,此外存内计算芯片通过架构创新可以提供综合性能全面兼顾的芯片及板卡,预计将在边侧推理场景中有着广泛的应用, 为广泛的边缘AI业务提供服务。
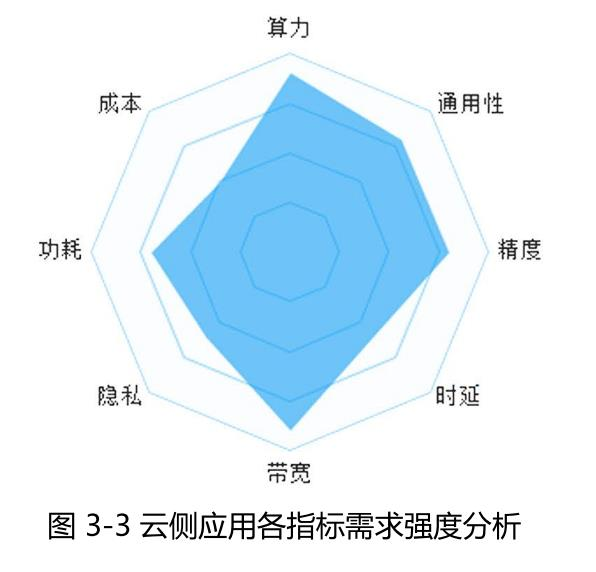
存内计算可通过多核协同集成大算力芯片,结合可重构设计打造 通用计算架构,存内计算作为智算中心下一代关键AI芯片技术,正面向 大算力、通用性、高计算精度等方面持续演进,有望为智算中心提供 绿色节能的大规模AI算力。
四、存内计算五大技术挑战
1. 新器件成熟度低,制造工艺难升级
2. 电路设计影响芯片算效提升
3. 芯片架构场景通用性及规模扩展能力较差
4. EDA工具链尚未健全
5. 软件及算法生态不完善
五、存内计算五大发展建议
中国移动结合算力网络业务发展诉求,提出存内计算发展建议,与业界共进,加速产业化进程:
1. 协同先进封装技术,实现不同方案相结合
2. 优化电路与芯片架构,保障能效优势和演进能力
3. 加速EDA工具孵化,缩短芯片研发周期
4. 构建开发生态与编程框架,加速应用规模发展
5. 产学研紧密协同,推动端侧到云侧演进
白皮书最后,中国移动作为算力网络新发展理念的引领者和实践者,提出了针对技术、产业、生态三个方面的倡议。知存科技作为存内计算领域的企业先行者,将响应倡议,继续联合各环节产业链条,共同攻关存算一体核心技术、共同加快存算一体产业成熟、共同推动存算一体生态繁荣,助力国家实现计算领域的原创科技创新和引流。









